1. 持久内存编程介绍
这本书描述了编写使用持久内存的应用程序的编程技术。它是为有经验的软件开发人员编写的,但是我们假设您以前没有使用持久内存的经验。我们用各种编程语言提供了许多代码示例。大多数程序员都会理解这些示例,即使他们以前没有使用过例子中所用的特定语言。
注意:所有代码示例都可以在GitHub存储库(https:// github.com/Apress/programming-persistent-memory)找到,包括构建和运行它的指令。
有关持久性内存的其他文档、示例程序、教程以及本书中大量使用的持久性内存开发工具包(PMDK)的详细信息,请参见http://pmem.io。 市场上的持久性内存产品可以以多种方式使用,其中许多方式对应用程序是透明的。例如,我们遇到的所有持久性内存产品都支持存储接口和标准文件API,就像任何固态磁盘(SSD)一样。访问SSD上的数据很简单,而且很容易理解,因此我们认为这些用例超出了本书的范围。相反,我们专注于内存方式的访问,应用程序管理驻留在持久内存中的字节可寻址数据结构。我们描述的一些用例是易失性的,只使用持久内存作为其容量扩充,而忽略了它是持久的这一事实。然而,本书的大部分内容都是针对持久性使用场景的,在这些场景中,放置在持久性内存中的数据结构有望在崩溃和电源故障中幸存下来,并且本书中描述的技术在这些事件中保持了这些数据结构的一致性。
1.1 高层示例程序
为了说明如何使用持久内存,我们从一个示例程序开始,演示由一个名为libpmemkv的库提供的键值存储。清单1-1显示了一个完整的C++程序,它在持久内存中存储三个键值对,然后遍历键值存储,打印所有的键值对。这个例子可能看起来微不足道,但是这里展示了几个有趣的组件。清单下面的描述显示了程序的功能。
Listing 1-1. A sample program using libpmemkv
37 #include <iostream>
38 #include <cassert>
39 #include <libpmemkv.hpp>
40
41 using namespace pmem::kv;
42 using std::cerr;
43 using std::cout;
44 using std::endl;
45 using std::string;
46
47 /*
48 * for this example, create a 1 Gig file
49 * called "/daxfs/kvfile"
50 */
51 auto PATH = "/daxfs/kvfile";
52 const uint64_t SIZE = 1024 * 1024 * 1024;
53
54 /*
55 * kvprint -- print a single key-value pair
56 */
57 int kvprint(string_view k, string_view v) {
58 cout << "key: " << k.data() <<
59 " value: " << v.data() << endl;
60 return 0;
61 }
62
63 int main() {
64 // start by creating the db object
65 db *kv = new db();
66 assert(kv != nullptr);
67
68 // create the config information for
69 // libpmemkv's open method
70 config cfg;
71
72 if (cfg.put_string("path", PATH) != status::OK) {
73 cerr << pmemkv_errormsg() << endl;
74 exit(1);
75 }
76 if (cfg.put_uint64("force_create", 1) != status::OK) {
77 cerr << pmemkv_errormsg() << endl;
78 exit(1);
79 }
80 if (cfg.put_uint64("size", SIZE) != status::OK) {
81 cerr << pmemkv_errormsg() << endl;
82 exit(1);
83 }
84
85
86 // open the key-value store, using the cmap engine
87 if (kv->open("cmap", std::move(cfg)) != status::OK) {
88 cerr << db::errormsg() << endl;
89 exit(1);
90 }
91
92 // add some keys and values
93 if (kv->put("key1", "value1") != status::OK) {
94 cerr << db::errormsg() << endl;
95 exit(1);
96 }
97 if (kv->put("key2", "value2") != status::OK) {
98 cerr << db::errormsg() << endl;
99 exit(1);
100 }
101 if (kv->put("key3", "value3") != status::OK) {
102 cerr << db::errormsg() << endl;
103 exit(1);
104 }
105
106 // iterate through the key-value store, printing them
107 kv->get_all(kvprint);
108
109 // stop the pmemkv engine
110 delete kv;
111
112 exit(0);
113 }
- 第57行:定义了一个小的辅助函数kvprint(),被调用时打印一个键值对。
- 第63行:main()的第一行,是每个C++程序开始执行的地方。我们首先使用引擎名“cmap”实例化一个键值引擎。我们在第9章讨论其他类型的引擎。
- •第70行:cmap引擎从配置结构获取配置参数。参数“path”配置为“/daxfs/kvfile”,它是DAX文件系统中持久内存文件的路径;参数“size”设置为SIZE。第3章描述如何创建和装载DAX文件系统。
- 第93行:我们向store中添加了几个键值对。键值存储的特征是使用简单的操作,比如put()和get();在本例中我们只显示put()。
- 第107行:使用get_all()方法,遍历整个键值存储区,在get_all()中调用我们写的kvprint()打印每个对。
1.1.1 有什么不同
几乎每种编程语言都有各种各样的键值库。清单1-1中的持久内存示例则不同,因为键值存储本身位于持久内存中。为了进行比较,图1-1显示了如何使用传统存储放置键值存储。
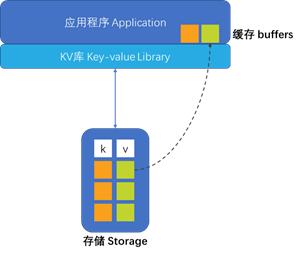
当图1-1中的应用程序想要从键值存储中获取一个值时,必须在内存中分配一个缓冲区来保存结果。这是因为这些值保存在块存储中,应用程序无法直接寻址。访问一个值的唯一方法是将其放入内存,唯一的方法是从存储设备中读取完整的块,这只能通过块I/O访问。现在考虑图1-2,其中的键值存储与我们的示例代码一样位于持久内存中。
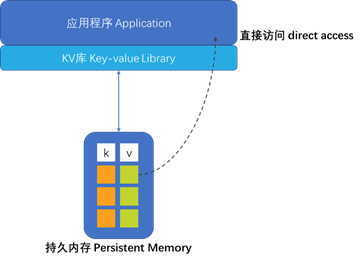
通过持久内存键值存储,应用程序可以直接访问值,而无需首先在内存中分配缓冲区。清单1-1中的kvprint()例程将通过引用实际的键和值来调用,直接访问它们在持久内存中所处的位置——这是传统存储做不到的。实际上,甚至键值存储库用来组织其数据的数据结构也可以直接访问。当基于存储的键值存储库需要进行小的更新(例如64字节)时,它必须将包含这些64字节的存储块读入内存缓冲区,更新64字节,然后写出整个块以使其持久化。这是因为存储访问只能使用块I/O进行,通常一次只能使用4K字节,因此更新64字节的任务需要先读取4K,然后再写入4K。但是对于持久性内存,更改64字节的相同示例只会将64字节直接写入持久性。
1.1.2 性能不同
将数据结构从存储移到持久内存并不只意味着支持更小的I/O尺寸;这是一个基本的性能差异。为了说明这一点,图1-3显示了不同类型的媒体之间的延迟层次结构,这些媒体是数据可以在程序中任何给定时间驻留的地方。
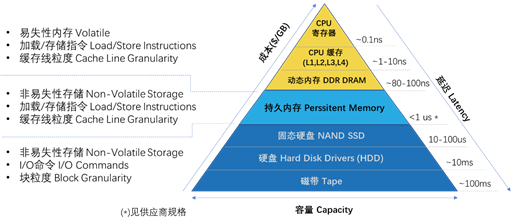
如金字塔所示,持久内存提供类似于内存的延迟(以纳秒为单位),同时提供持久性。块存储提供持久性,延迟从微秒开始,然后根据技术的不同而增加。持久内存同时表现为内存和存储器,这方面的能力是独一无二的。
1.1.3 编程复杂性
也许我们例子中最重要的一点是,程序员仍然使用通常与键值存储相关联的熟悉的get/put接口。数据结构在持久内存中的事实被libpmemkv提供的高级API抽象掉了。只要满足应用程序的需求,使用尽可能高级别抽象的原则将是本书中反复出现的主题。我们首先介绍最高层的API;后面的章节将深入探讨程序员所需的低层细节。在最低层,直接对裸的持久内存编程需要硬件原子性、缓存flush和事务等方面的详细知识。像libpmemkv这样的高级库抽象了所有这些复杂性,并提供了更简单、更不易出错的接口。
1.1.4 libpmemkv 如何工作
像libpmemkv这样的高级库隐藏的所有复杂性在后面的章节中都有更详细的描述,现在我们先看看用于构建该库的模块。图1-4显示了应用程序使用libpmemkv时所涉及的完整软件栈。
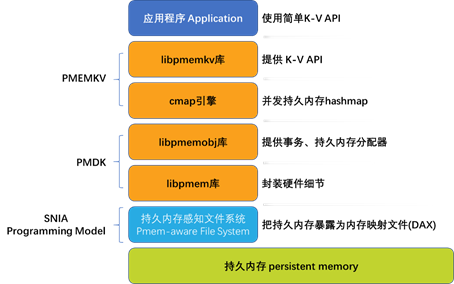
从图1-4的底部开始向上介绍这些组件:
- 持久内存硬件,通常连接到系统内存总线,并使用通用内存load/store操作进行访问;
- 支持持久内存感知的文件系统,它是一个内核模块,将持久内存作为文件公开给应用程序。这些文件可以通过内存映射来直接访问(缩写为DAX)。这种公开持久内存的方法由SNIA(存储网络行业协会)发布,并在第3章中详细描述。
- libpmem库,是PMDK的一部分。该库抽象了一些低层硬件细节,如缓存flush指令;
- libpmemobj库,是一个功能齐全的事务和持久内存分配库。(第7章和第8章更详细地描述了libpmemobj及其C++库)如果你不能找到满足你需求的数据结构,你将很可能需要使用这个库来实现你所需要的,如第11章中所描述;
- cmap引擎,为持久内存优化的并发哈希映射;
- libpmemkv库,提供清单1-1所示的API;
- 最后是使用libpmemkv API的应用程序。
虽然这里有很多组件在使用,但这并不意味着每个操作都需要运行大量的代码。某些组件仅在初始设置期间使用。例如,pmem-aware文件系统用于查找持久内存文件并执行权限检查;此后,它就完成了其应用程序数据路径的职责。PMDK库的设计目的是尽可能利用持久内存的直接访问。
1.2 后续内容
第1章到第3章提供了程序员开始持久内存编程所需的基本背景知识。这个阶段只用了一个简单的示例来说明;接下来的两章提供了持久内存硬件和操作系统级别的详细信息。后面和更高级的章节则为感兴趣者提供了更多细节。
1.3 本章小结
本章介绍如何使用libpmemkv这样的高级api进行持久内存编程,从而向应用程序开发人员隐藏持久内存的复杂细节。使用持久内存可以允许比基于块的存储更细粒度的访问和更高的性能。我们建议尽可能使用最高级别、最简单的API,并且只有在必要时才引入低层持久内存编程的复杂性。
后续:




