2 持久内存架构
本章概述了持久内存体系结构,同时重点介绍了硬件,以强调开发人员需要知道的需求和决策。
设计用于识别系统中是否存在持久内存的应用程序可以比使用其他存储设备运行得快得多,因为数据不必在CPU和速度较慢的存储设备之间来回传输。因为只使用持久内存的应用程序可能比动态随机访问内存(DRAM)慢,所以应用应该决定哪些数据驻留在DRAM内存中,哪些存储在持久内存中。
持久内存的容量比DRAM大很多倍;因此,应用程序可在持久内存中存储和处理的数据量也要大得多。这显著减少了磁盘I/O的数量,从而提高了性能并减少了存储介质的磨损。
在没有持久内存的系统上,不能放入DRAM的大型数据集必须分段处理或流式处理。当应用程序等待数据从磁盘页或从网络流式传输时,这会导致处理延迟。 如果工作数据集的大小适合持久内存和DRAM的容量,那么应用程序可以完全在内存中进行处理,而无需检查点或页面数据到存储器或从存储器中读取。这将显著提高性能。
2.1 持久内存特性
就像每项新技术一样,总是有新的事情需要考虑。持久内存也不例外。在设计和开发解决方案时,请考虑以下特征:
- 持久内存与DRAM不同。它的耐久性通常比NAND好几个数量级,并且应该在不磨损的情况下超过服务器的生命周期;
- 持久内存模块的容量可以比DRAM 内存大得多,并且可以在相同的内存通道上共存;
- 使用持久内存的应用程序可以就地更新数据,而无需序列化/反序列化数据;
- 持久内存是字节可寻址的,就像内存一样。应用程序只须更新所需的数据,而不需要任何读-修改-写(read-modify-write)的开销;
- 数据是CPU缓存一致的;
- 持久内存提供直接内存访问(DMA)和远程直接数据存取(RDMA)操作;
- 断电时写入持久内存的数据不会丢失;
- 权限检查完成后,可以从用户空间直接访问位于持久内存中的数据。数据访问路径上没有内核代码、文件系统页缓存或中断;
- 持久内存上的数据立即可用,即:
- 一旦系统通电,数据即可用;
- 应用程序不需要花时间预热缓存。它们可以在内存映射数据时立即访问数据;
- 驻留在持久内存中的数据不占用DRAM内存空间,除非应用程序将数据复制到DRAM内存以加快访问速度。
- 写入持久性内存模块的数据是系统本地的。应用程序负责跨系统复制数据。
2.2 支持持久内存的平台
Intel、AMD、ARM等平台供应商将决定如何在最低的硬件级别上实现持久内存。我们试图提供一个与供应商无关的视角,只是偶尔才给出特定于平台的详细信息。
对于具有持久内存的系统,故障原子性保证系统在电源或系统故障后始终可以恢复到一致状态。应用程序的故障原子性可以通过使用日志记录、刷新和内存存储屏障来实现。日志记录,无论是撤消还是重做,都可以确保在故障中断完成的最后一个原子操作的原子性。缓存刷新确保易失性缓存中保存的数据到达持久域,以便在发生突发故障时不会丢失。内存存储屏障(如x86体系结构上的SFENCE操作)有助于防止内存层次结构中的潜在重新排序,因为缓存和内存控制器可能会重新排序内存操作。例如,屏障确保在实际数据修改到位之前,数据的撤消日志副本被持久化到持久内存中。这保证了在发生故障时可以回滚最后一个原子操作。但是,在具有低级别操作(如写日志、缓存刷新和屏障)的用户应用程序中添加这样的故障原子性是非常重要的。持久内存开发工具包(PMDK)的开发是为了将开发人员从重新实现硬件复杂性中解放出来。
自从大多数文件系统都实现了元数据到存储设备的日志记录和刷新后,故障原子性应该已成了一个大家所熟悉的概念。
2.3 Cache层次体系
我们使用load、store操作来读写持久内存,而不是使用基于块的IO来读写传统的存储。我们建议阅读深入描述CPU架构的文档,因为每一代CPU都会引入新的特性、方法和优化。
以Intel架构为例,CPU缓存一般包含三层:L1、L2、L3。这个层次体系参照了到CPU核心的距离、速度、缓存大小。L1离CPU最近,最快,但最小。L2、L3缓存容量递增,但相对更慢些。图2-1显示了一个具有三级CPU缓存和一个具有三个内存通道的内存控制器的典型CPU微体系结构。每个内存通道都有一个DRAM内存和一个持久内存。在CPU缓存不包含在电源故障保护域中的平台上,当系统断电或崩溃时,CPU缓存中未刷到持久内存的任何数据修改都将丢失。在电源故障保护域中包含CPU缓存的平台上,将确保如果系统崩溃或断电,CPU缓存将刷到持久内存。我们将在即将到来的“电源故障保护域”一节中描述这些需求和功能。
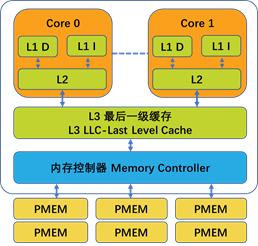
一级缓存(L1)是计算机系统中速度最快的内存。就访问优先级而言,L1缓存拥有CPU在完成特定任务时最可能需要的数据。一级缓存通常也分为两种方式:指令缓存(L1 I)和数据缓存(L1 D)。指令缓存处理关于CPU必须执行的操作的信息,而数据缓存保存要执行操作的数据。
二级缓存(L2)的容量大于一级缓存,但速度较慢。二级缓存保存下一步可能被CPU访问的数据。在大多数现代CPU中,一级和二级缓存都存在于CPU内核上,每个内核都有专用的缓存。
三级缓存(L3)是容量最大的缓存,但也是三个缓存中最慢的。它也是CPU上所有核心之间的一个通用共享资源,可以在内部分区,以允许每个核心具有专用的L3资源。
从DRAM内存或者持久内存读上来的数据通过内存控制器传输到L3 缓存,传播到L2 缓存,最终到L1 缓存,供CPU消费。当处理器为执行一个操作寻找数据时,先到L1 缓存中查找,找到则称为命中(cache hit),否则到L2 缓存中查找、然后到L3 缓存中查找,如果都没找到,就到内存中查找。每次找不到称为缓存失效(cache miss)。如果内存中找不到,就到磁盘上加载页到内存中。
当CPU写数据时,写到L1 缓存,然后在某个及时时点,写到L2、L3、内存。
没有持久内存的系统里,软件通过写非易失性存储设备来持久化数据,如:SSD、HDD、SAN、NAS,或者云上的一个卷。以此保护数据,以避免应用或者系统crash,造成数据丢失。关键数据需要手动刷到存储上,如:调用msync()、fsync()、或者 fdatasync() 方法,将未提交的内存中的脏数据刷到非易失性存储。文件系统提供fdisk或者chkdsk工具来检查或者尝试修复损坏的文件系统。文件系统不能保护用户数据不受坏块的影响。这种场景下需要应用程序检测并恢复。这就是为什么数据库使用如下各种技术:事务更新、重做日志、撤消日志、校验码。
应用内存映射持久内存地址范围到应用自已的内存空间。因此应用必须确保检查和保障数据的完整性。后面会描述我们在持久内存环境下,如何做才能达成数据的一致性和完整性。
2.4 断电保护域
一个系统包含一个或多个CPU、易失性内存或持久内存、非易性存储设备(如:SSD或HDD)。系统平台硬件支持持久域的概念,也称作断电保护域。
系统平台硬件支持持久域(也称为断电保护域)的概念。根据平台的不同,持久域可以包括持久内存控制器和写入队列、内存控制器写入队列和CPU缓存。一旦数据到达持久域,就可以在系统重新启动的过程中恢复它。也就是说,如果数据位于受电源故障保护的硬件写入队列或缓冲区内,则域应用程序应假定它是持久的。例如,如果发生电源故障,将使用备用能源(平台保证此目标的存储用能源)从断电保护域刷数据到持久设备。尚未进入受保护域的数据将丢失。
同一个系统中可能存在多个持久域,例如,在具有多个物理CPU的系统上。系统还可以提供一种机制,用于对平台资源进行分区以进行隔离。这必须以这样的方式完成:SNIA NVM编程模型的行为可以从每个兼容的卷或文件系统得到保证。(第3章描述了应用于操作系统和文件系统的编程模型。该章中的“检测平台功能”部分描述了应用程序应执行的逻辑,以检测平台功能,包括断电保护域。后面的章节将深入讨论为什么、如何以及何时应用程序应该刷数据(如果需要的话),以确保数据在受保护的域和持久内存中是安全的。)
当计算机系统的电源中断时,易失性存储器会丢失其内容。但持久内存像非易失性存储设备一样,即使在没有系统电源的情况下,也会保留其内容。物理上保存到持久性存储介质的数据称为静态数据(Data at rest)。与之对应为飞行数据(Data in-flight),具有以下含义:
- 已发送到持久性内存设备但尚未物理提交到媒体的写入;
- 正在进行但尚未完成的任何写入;
- 临时缓冲或缓存在CPU缓存或内存控制器中的数据。
当系统正常重新启动或关闭时,系统将保持电源,并确保冲刷CPU缓存和内存控制器的所有内容完成,以便将任何正在运行或未提交的数据成功写入持久内存或非易失性存储。当发生意外电源故障时,并且假设没有可用的不间断电源(UPS),系统必须在电源和分布在其周围的电容器中有足够的存储能量,以便在电源完全耗尽之前冲刷数据。任何未冲刷的数据都将丢失且无法恢复。
异步DRAM刷新(ADR,Asynchronous DRAM Refresh)是Intel产品支持的一项功能,它刷新受写保护的数据缓冲区并将DRAM置于自刷新状态。在断电事件或系统崩溃期间,此过程至关重要,以确保数据在持久内存上处于安全和一致的状态。默认情况下,ADR不刷新处理器缓存。支持ADR的平台只包括持久内存和持久域中内存控制器的写挂起队列。这就是应用程序必须使用CLWB、CLFLUSHOPT、CLFLUSH、non-temporal stores或WBINVD机器指令刷新CPU缓存中的数据的原因。
增强异步DRAM刷新(eADR,Enhanced Asynchronous DRAM Refresh)要求在ADR事件开始之前调用不可屏蔽中断(NMI)例程来刷新CPU缓存。在eADR平台上运行的应用程序不需要执行刷新操作,因为硬件应该自动刷新数据,但是仍然需要执行SFENCE操作来保持写顺序的正确性。只有当存储在全局可见时才应将其视为持久存储,这是SFENCE保证的。
下图显示了ADR和eADR持久域:

ADR是持久性存储器的一个强制性平台要求。一旦接收到所有数据,内存控制器中的写入挂起队列(WPQ)就会向写入程序确认数据的接收。尽管数据尚未到达持久介质,但支持ADR的平台可以保证在断电事件发生时成功写入数据。在崩溃或电源故障期间,只有在平台支持eADR的情况下,才能保证通过CPU缓存传输的数据被刷到持久介质中。在只支持ADR的平台上,数据将丢失。
扩展持久域以包含CPU缓存的挑战在于,CPU缓存相当大,并且它所需的能量比典型电源中的电容器实际所能提供的能量要多得多。这意味着平台必须包含电池或使用外部不间断电源。为支持持久内存的每台服务器都需要一个电池,这通常不实用,也不划算。电池的使用寿命通常比服务器短,这会引入额外的维护例程,从而减少服务器的正常运行时间。使用电池时也会对环境造成影响,因为必须正确处理或回收电池。服务器或设备原始设备制造商完全有可能在其产品中包含电池。
由于一些设备和服务器供应商计划使用电池,而且由于平台有一天会在持久域中包含CPU缓存,因此ACPI中有一个属性可用,以便BIOS可以在跳过CPU刷新时通知软件。在带有eADR的平台上,不需要手动刷新缓存线。
2.5 刷新、排序和屏障
除了WBINVD是内核操作外,表2-1(见持久内存Intel机器指令章节)中的机器指令都是用户空间的,Intel和AMD CPU都支持。Intel采用与持久内存一起工作的SNIA NVM编程模型。该模型允许使用字节寻址操作(如:load/store)的直接访问(DAX) 。然而,缓存中的数据在没有进入持久域之前,其持久化得不到保障。
X86架构以更优化的方式提供了一系列指令来冲刷缓存线。还有已经支持的X86指令,如:non-temporal stores、CLFLUSH和WBINVD, 以及两个新指令: CLFLUSHOPT 和CLWB。这两个新指令都必须后跟SFENCE来确保所有冲刷操作完成。这些操作都在用户空间提供支持。详细参考见:开发手册 https://software.intel.com/en-us/articles/intel-sdm。
非临时性存储(Non-temporal stores)操作暗示要写的数据不会很快被读取,所以未放到CPU 缓存。所以也没有保持在CPU 缓存中所获得的好处,并且可能被来自缓存的有用的其他数据所替换。
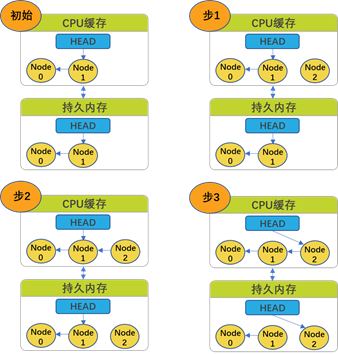
从用户空间直接刷到持久内存,不用调用内核,所以非常高效。需要硬件和操作系统支持。尽管CPU支持,也必须操作系统支持,指示该操作可以安全使用。操作系统需要通过调用msync()来提供控制点,例如,文件系统元数据的变化需要作为msync()操作的一部分。为了更好的理解指令顺序,考虑这个非常简单的链表例子。我们的伪代码分为三步来添加一个新的节点到已包含两个节点的链表。这些步骤见下图:
- 创建新节点(node2);
- 更新节点指针(next pointer)来指向最后的节点(Node 2 → Node 1);
- 更新头指针指向新的节点(Head → Node 2)。
图2-3(第三步)显示, CPU 已缓存的头指针版本被更新,但Node 2指向Node 1的指针还没有被更新到持久内存中。这是因为硬件可以选择要提交的缓存线,并且顺序不一定与源码的执行流一致。如果系统或者应用在此点崩溃,持久内存状态将是不一致的,数据结构也不再可用。
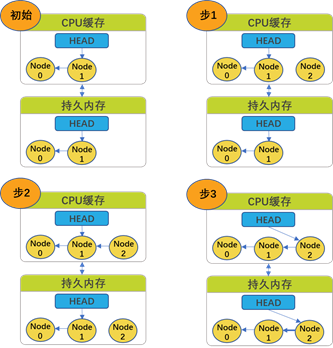
为了解决该问题,我们介绍内存存储屏障技术来确保写操作的顺序。从相同的初始状态开始,伪代码现在看起来是这个样子:
- 创建一个新节点;
- 更新该节点指针(next pointer)指向链表最后一个节点;并且执行store barrier/fence 操作;
- 更新头指针指向新的节点。
如图2-4所示:我们可以看到,在第三步store barrier/fence操作在更新head pointer之前,等待把指针从Node2指向Node1。这些在CPU 缓存中的更新与持久内存中的版本一致,所以现在是全局可见的。因为存储屏障不提供原子性和数据完整性,所以这是个过分简单化的解决方式,完整的解决方案应该是使用事务(transactions)来确保数据被原子性的更新。
当内存池被打开时,PMDK会检查平台、CPU和持久内存的特性,然后使用优化指令来保护写顺序。(内存池Memory pools是那些被内存映射到进程地址空间的文件,后续有详细解释)。
为了使应用开发者从硬件复杂性解脱出来,不用研究每个平台和设备,并实现特定的代码,libpmem库提供函数支持,当应用使用优化的flush、或者flush到内存映射文件时是安全的。
为了简化程序,我们鼓励开发者使用公用库,如:PMDK中的libpmem和其他库。 libpmem库旨在检查到平台带电池时,自动将flush 调用转为简单的 SFENCE 指令。第五章详细介绍PMDK中的核心库。后面的章节更深入地介绍了每个库,以帮助大家来理解这些库的API及特性。
2.6 数据可见性
数据可见性指数据对其他进程或线程是可见的,并且当它在持久域里时是安全的,当在应用中使用持久内存时,理解这点至关重要。
在上面的图2-2 、2-3 例子中,在CPU 缓存中的数据更新对其他进程/线程是可见的。可见性和持久性通常不是一回事儿,对持久内存的变更在他们持久化之前经常对其他正在运行的线程是可见的。可见性的工作方式与普通DRAM相同,由给定平台的内存模型排序和可见性规则描述(例如,有关Intel平台的可见性规则,请参阅:Intel Software Development Manual for the visibility rules for Intel platforms)。
变更的持久化通过三种方法达到:
- 通过调用持久化标准存储API (linux上调用msync,Windows上调用FlushFileBuffers);
- 如果支持的话,通过使用优化的flush;
- CPU cache已经考虑了持久化。
这就是为什么我们使用flushing和fencing操作的原因。用C写的伪代码样例看起来是这个样子的:
open() // Open a file on a file system 打开一个文件
...
mmap() // Memory map the file 映射该文件
...
strcpy() // Execute a store operation 执行存储操作
... // Data is globally visible
msync() // Data is now persistent 执行持久化2.7 持久内存Intel机器指令
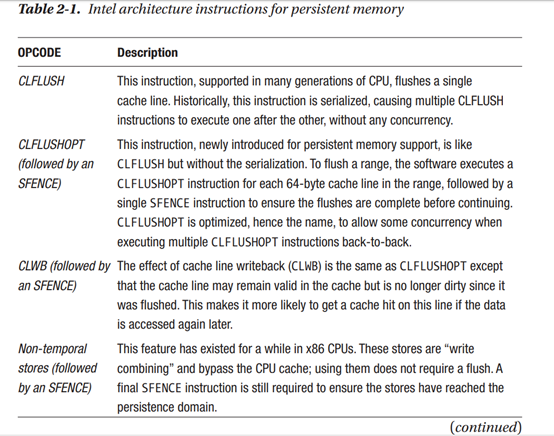
适用于基于Intel和AMD的ADR平台,执行Intel 64和32 架构的store指令不足以使数据持久化,因为数据可能无限期地驻留在CPU 缓存中,并且断电时会丢失。需要另外的缓存flush操作使存储持久化。重要的是,这些无特权缓存flush操作可以从用户空间调用,这意味着应用决定什么时间在哪里设置fence并且flush数据。表2-1简要介绍了这些指令。想要了解更多信息,请参考the Intel 64 and 32 Architectures Software Developer Manuals 手册,网址:https://software.intel.com/en-us/articles/intel-sdm。开发者应该首先聚焦于CLWB和Non-Temporal Stores,如果这些可用的话,如有必要再去找其他的方式。表2-1列出了完整性操作码。

2.8 检测平台的能力
服务器平台、CPU、持久性内存特性和能力通过BIOS和ACPI暴露给操作系统,可以被应用查询。应用应当假设所运行的硬件没有全部优化。即使物理硬件支持,虚拟化技术可能没有把这些特性暴露给用户,或者你的操作系统可能没有实现这些特性。严格意义上来说,我们鼓励开发者使用库,如:PMDK中的库,执行所需特性检测或者在应用代码中实现这些检测。
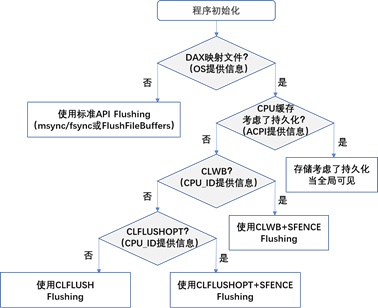
如图2-5所示,libpmem实现的流,它首先验证内存映射文件(称为内存池),驻留在启用了DAX功能的文件系统上,并由物理持久内存支持。第3章详细介绍了DAX。
在Linux上,通过安装带有“-o dax”选项的XFS或ext4文件系统来实现直接访问。在Microsoft Windows上,当使用DAX选项创建和格式化卷时,NTFS将启用DAX。如果文件系统未启用DAX,则应用程序应回到使用msync()、fsync()或FlushFileBuffers()的传统方法。如果文件系统启用了DAX,则下一个检查是通过验证CPU缓存是否被视为持久的,来确定平台是否支持ADR或eADR。在一个eADR平台上,CPU缓存被认为是持久的,不需要进一步的操作。任何写入的数据都将被认为是持久的,因此不需要执行任何冲刷,这是一个重要的性能优化。在ADR平台上,下一个事件序列根据前面描述的Intel机器指令确定最佳冲刷操作。
【梳理后的步骤描述】
图2-5 libpmem实现流图:
- 程序初始化,确认文件系统上基于持久内存的内存映射文件(也叫内存池)是否启动了DAX特性。在linux上,通过使用mount命令的 -o dax 选项来挂载XFS 或者 ext4文件系统。在windows上,当创建和格式化NTFS格式时使用DAX选项;
- 如果文件系统不支持DAX,那么应用将使用老方法msync()、fsync()或者FlushFileBuffers();
- 如果文件系统支持DAX,那么接下来检测平台是否支持ADR或者eADR,确认 CPU 缓存是否考虑了持久化;
- 在eADR平台CPU cache已经考虑了持久化,所以不需要进一步的操作;被写的任何数据都考虑了持久化,所以不需要执行任何flush操作,这会有显著的性能提升;
- 在ADR平台,下一个事件序列根据前面描述的Intel机器指令确定最佳冲刷操作。
2.9 应用启动和恢复
除了检测平台特性,应用还要确认平台先前是否优雅的停止与重启。图2-6 示意了PMDK执行的检查流程。
某些持久性内存设备(如Intel Optane DC persistent memory)提供智能计数器,可以查询这些计数器以检查运行状况和状态。一些库(如libpmemobj)查询BIOS、ACPI、OS和持久内存模块信息,然后执行必要的验证步骤,以确定哪个冲刷操作最适合。
我们前面已经描述过,如果系统断电,那么电源和平台中应该有足够的存储能量来成功地冲刷内存控制器的WPQ和持久内存设备上写缓冲区的内容。成功完成后,数据将被视为一致。如果此进程失败,因为在成功冲刷所有数据之前耗尽了所有存储的能量,则持久内存模块将报告脏关机。脏关机表示设备上的数据可能不一致。这可能需要也可能不需要从备份中恢复数据。您可以在您的平台和持久性内存设备的RAS(可靠性、可用性、可维护性)文档中找到有关此过程以及发送了哪些错误和信号的更多信息。第17章也进一步讨论了这一点。
假设没有dirty shutdown 指示,应用应检测持久内存设置是否报告了poison blocks (见图2-6)。Poisoned blocks表示物理媒体上的该区域已经坏了。
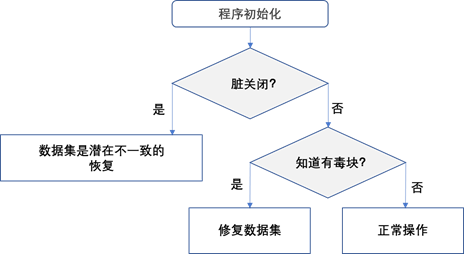
如果因为媒体的持久性,应用没有在启动时检测这些项,将卡在无限循环,例如:
- 应用启动;
- 读取内存地址;
- 遇到了posion;
- 崩溃重启;
- 启动并从上次停止处重启;
- 读取在上次重启处相同内存地址,;
- 应用或系统崩溃;
- …
- 无限重启或者手动干预。
ACPI规范定义了操作系统实现的地址范围清理(ARS)操作。这允许操作系统在持久内存的内存地址范围内执行运行时后台扫描操作。系统管理员可以手动启动ARS。其目的是在应用程序之前识别坏的或潜在的坏内存区域。如果ARS发现一个问题,硬件可以向操作系统和应用程序提供一个状态通知,那么应用就可以优雅的进行处理。如果坏地址范围包含数据,则需要实现一些重建或还原数据的方法。第17章更详细地描述了ARS。
开发者在应用代码中可以自由地直接实现这些特性。然而,PMDK中的库处理了这些复杂情况,并且该库会维持对每代产品的支持,并提供稳定的API。【自己实现这些工作量就会很大,也无法针对每代产品进行测试支持。】这给了一个对未来的保障,而不用去理解每个CPU或者持久内存产品的复杂细节。
2.10 后续内容
第3章继续从内核和用户空间的角度提供基础信息。我们描述了Linux和Windows等操作系统如何采用和实现SNIA非易失性编程模型,该模型定义了支持持久内存的各种用户空间和操作系统内核组件之间的推荐行为。后面的章节建立在第1章到第3章的基础之上。
2.11 本章小结
本章定义了持久内存及其特性,概述了CPU缓存的工作方式,并描述了为什么直接访问持久内存的应用程序必须承担冲刷CPU缓存的责任。我们主要关注硬件实现。用户库(如随PMDK提供的用户库)承担体系结构和硬件特定操作的责任,并允许开发人员使用简单的API来实现它们。后面的章节将更详细地描述PMDK库,并展示如何在应用程序中使用它们。




