11 为持久内存设计数据结构
利用持久内存的独特特性,如字节可寻址性、持久性和就地更新,我们可以构建比任何需要序列化或刷新到磁盘的数据结构都快得多的数据结构。然而,这是有代价的。必须仔细设计算法,以便通过flush CPU缓存或使用非临时存储和内存栅栏来保持数据的一致性,从而正确地持久化数据。本章描述如何设计这些数据结构和算法,并说明它们应该具有哪些属性。
11.1 连续数据结构和碎片
由于堆的生命周期很长,碎片化是为持久性内存设计数据结构时要考虑的最关键的因素之一。持久堆可以与应用程序的不同版本共存数年。在易失性用例中,堆在应用程序退出时被销毁。堆的寿命通常用小时、天或周来衡量。
为内存分配使用文件系统支持的页,使得很难利用操作系统提供的最小化碎片的机制,例如将不连续的物理内存表示为一个连续的虚拟区域。我们可以手动以低粒度管理虚拟内存,为用户空间中的对象生成页级的碎片整理机制。但这种机制可能导致物理内存完全碎片化,无法利用巨大的页面。这可能会导致页表缓冲(TLB)未命中的次数增加,从而显著减慢整个应用程序的速度。为了有效地利用持久内存,应该以最小化碎片的方式设计数据结构。
11.1.1 内部和外部碎片
内部碎片是指在分配的块内过度配置的空间。分配器总是以固定大小的chunks或buckets返回内存。分配器必须确定每个bucket的大小以及它提供的不同大小的bucket的数量。如果内存分配请求的大小与预定义的bucket大小不完全匹配,分配器将返回一个更大的bucket。例如,如果应用程序请求200KiB的内存分配,但分配器的bucket大小为128KiB和256KiB,则请求是从可用的256KiB bucket分配的。由于内部对齐要求,分配器通常必须返回一个大小可被16整除的内存chunk。
当可用内存分散在小块中时,会发生外部碎片。例如,想象一下使用4KiB分配的整个内存。如果我们每释放一次其他分配,我们就有一半的可用内存;但是,我们不能一次分配超过4KiB,因为这是任何连续可用空间的最大大小。图11-1说明了这个碎片,其中红色单元格表示分配的空间,白色单元格表示可用空间。

在持久内存中存储一系列元素时,可以使用以下几种数据结构:
- 链表Linked list:每个节点都是从持久内存中分配的;
- Dynamic array (vector)::一种数据结构,它将内存预先分配到更大的块中。如果没有新元素的可用空间,它将分配一个容量更大的新数组,并将所有元素从旧数组移动到新数组;
- Segment vector:固定大小数组的列表。如果任何段中没有剩余可用空间,则分配一个新的段。
考虑每个数据结构的碎片:
- 对于链表,分段效率取决于节点大小。如果它足够小,那么内部碎片可能会很高。在节点分配期间,每个分配器都将返回内存,内存的对齐方式可能与节点大小不同;
- 使用动态数组会减少内存分配,但每个分配都有不同的大小(大多数实现是前一个的两倍),这会导致更高的外部碎片;
- 使用段向量,段的大小是固定的,因此每个分配都有相同的大小。这实际上消除了外部碎片,因为我们可以为每个释放的段分配一个新的段。
11.1.2 原子性和一致性
保证一致性需要正确的存储顺序,并确保数据被持久存储。要使原子存储大于8字节,必须使用一些附加机制。本节介绍几种机制,并讨论它们的内存和时间开销。对于时间开销,重点是分析使用的flush和内存栅栏的数量,因为它们对性能的影响最大。
11.1.3 事务
保证原子性和一致性的一种方法是使用事务(已在第7章中详细描述)。在这里,我们关注如何设计一个数据结构来有效地使用事务。使用事务的示例数据结构在本章后面的“带版本控制的排序数组”部分中进行了描述。
事务是保证一致性的最简单解决方案。虽然使用事务很容易使大多数操作原子化,但必须记住两项:首先,使用日志记录的事务总是会引入内存和时间开销;其次,在撤销日志记录的情况下,内存开销与您修改的数据大小成正比,而时间开销则取决于快照的数量。每个快照必须在修改快照数据之前持久化。
在为持久性内存设计数据结构时,建议使用面向数据的方法。其思想是以这样一种方式存储数据,即CPU对数据的处理是缓存友好的。想象一下,必须存储由两个整数值组成的1000条记录的序列。这有两种方法:要么使用清单11-1所示的两个整数数组,要么使用清单11-2所示的一个成对数组。第一种方法是SoA(数组的结构),第二种是AoS(结构的数组)。
Listing 11-1. SoA layout approach to store data
struct soa {
int a[1000];
int b[1000];
};
Listing 11-2. AoS layout approach to store data
std::pair<int, int> aos_records[1000];哪种方式更好,取决于对数据的访问模式。如果程序经常更新元素的两个字段,那么AoS解决方案更好。但是,如果程序只更新所有元素的第一个变量,那么SoA解决方案最有效。
对于使用易失性内存的应用程序,主要关注的是单指令多数据(SIMD)处理的缓存未命中和优化。SIMD是Flynn分类法中的一类并行计算机,它具有多个处理元件,可以同时对多个数据点执行相同的操作。这种机器利用数据层的并行机制,而不是利用并发性:在给定时刻同时(并行)计算,但只有一个处理指令。
虽然这些对于持久内存来说仍然是有效的,但是开发人员在使用事务时必须考虑快照性能。快照一个连续的内存区域总是比快照几个较小的区域要好,这主要是因为使用较少的元数据所产生的开销较小。在将数据从基于DRAM的实现迁移到持久内存时,考虑这些因素的高效数据结构布局对于避免将来的问题是必不可少的。
清单11-3给出了两种方法;在本例中,我们希望将第一个整数增一。
Listing 11-3. Layout and snapshotting performance
37 struct soa {
38 int a[1000];
39 int b[1000];
40 };
41
42 struct root {
43 soa soa_records;
44 std::pair<int, int aos_records[1000];
45 };
46
47 int main()
48 {
49 try {
50 auto pop = pmem::obj::pool<root>::create("/daxfs/pmpool",
51 "data_oriented", PMEMOBJ_MIN_POOL, 0666);
52
53 auto root = pop.root();
54
55 pmem::obj::transaction::run(pop, [&]{
56 pmem::obj::transaction::snapshot(&root->soa_records);
57 for (int i = 0; i < 1000; i++) {
58 root->soa_records.a[i]++;
59 }
60
61 for (int i = 0; i < 1000; i++) {
62 pmem::obj::transaction::snapshot(
63 &root->aos_records[i].first);
64 root->aos_records[i].first++;
65 }
66 });
67
68 pop.close();
69 } catch (std::exception &e) {
70 std::cerr << e.what() << std::endl;
71 }
72 }- 第37-45行: 我们定义了两种不同的数据结构来存储整数的记录。第一个是SoA,我们将整数存储在两个独立的数组中。第44行展示了一个成对的数组-AoS;
- 第56-59行: 我们通过一次快照整个数组来利用SoA的布局。然后我们可以安全地修改每个元素;
- 第61-65行: 当使用AoS时,我们被迫在每次迭代中对数据进行快照—我们要修改的元素在内存中不连续。
使用事务的数据结构的示例在本章后面的“支持事务的哈希表”和“事务哈希表和选择性持久化”部分中展示。
11.1.4 写时拷贝和版本控制
另一种保持一致性的方法是copy-on-write(CoW)技术。在这种方法中,每当您想修改持久数据结构的某个部分时,每次修改都会在新位置创建一个新版本。例如,链表中的节点可以使用如下所述的CoW方法:
- 在列表中创建元素的副本。如果副本动态分配到持久内存中,则还应将指针保存在持久内存中,以避免内存泄漏。如果执行失败,并且应用程序在分配后崩溃,则在应用程序重新启动时,将无法访问新分配的内存。
- 修改副本并持久化变化。
- 原子地使用副本更改原始元素并持久化更改,然后根据需要释放原始节点。此步骤成功完成后,元素将更新并处于一致状态。如果在此步骤之前发生崩溃,则原始元素不会被触及。
尽管与事务相比,使用这种方法可能更快,但实现起来要困难得多,因为必须手动持久化数据。
Copy-on-write通常在多线程系统中运行良好,在这些系统中,引用计数或垃圾收集等机制用于释放不再使用的副本。尽管这类系统超出了本书的范围,但第14章描述了多线程应用程序中的并发性。版本控制是一个非常类似于写时拷贝的概念。不同之处在于,这里保存的数据字段不止一个版本。每次修改都会创建字段的新版本,并存储有关当前字段的信息。本章后面的“带版本控制的排序数组”中给出的示例,在排序数组的插入操作的实现中展示了此技术。在前面的示例中,只保留变量的两个版本,旧版本和当前版本作为双元素数组。插入操作交替地将数据写入这个数组的第一个和第二个元素。
11.1.5 选择性持久化
持久内存比磁盘存储快,但比DRAM慢。可以实现混合数据结构,其中一些部分存储在DRAM中,而一些部分存储在持久内存中,以提高性能。在DRAM中缓存以前计算的值或数据结构中经常访问的部分可以改善访问延迟并提高总体性能。
数据并不总是需要存储在持久内存中。相反,它可以在应用程序重新启动期间重建,以便在运行时提供性能改进,因为它可以从DRAM访问数据,并且不需要事务。这种方法的一个例子出现在“事务哈希表和选择性持久化”章节中。
11.2 示例数据结构
本节介绍了几个使用前面描述的方法设计的数据结构示例,以确保一致性。代码是用C++编写的,使用了libpmemobj-cpp库。有关此库的详细信息,请参阅第8章。
11.2.1 事务哈希表
我们给出了一个使用libpmemobj-cpp的事务和容器实现的哈希表示例。哈希表是一种数据结构,它可以将键映射到值并保证O(1)查找时间。它通常被实现为一个bucket数组(一个bucket是一个可以容纳一个或多个键值对的数据结构)。将新元素插入哈希表时,哈希函数将应用于元素的键。结果值被视为插入元素的bucket的索引。不同键的散列函数的结果可能相同;这称为冲突。解决冲突的一种方法是使用分离链接法。这种方法在一个bucket中存储多个键值对;清单11-4中的示例就使用了这种方法。 为了简单起见,清单11-4中的哈希表只提供const Value&get(const std::string &key)和void put(const std::string &key, const Value &value)方法。它使用固定数量的buckets。扩展此数据结构以支持remove操作并拥有动态数量的bucket,是留给您的练习作业。
Listing 11-4. Implementation of a hash table using transactions
38 #include <functional>
39 #include <libpmemobj++/p.hpp>
40 #include <libpmemobj++/persistent_ptr.hpp>
41 #include <libpmemobj++/pext.hpp>
42 #include <libpmemobj++/pool.hpp>
43 #include <libpmemobj++/transaction.hpp>
44 #include <libpmemobj++/utils.hpp>
45 #include <stdexcept>
46 #include <string>
47
48 #include "libpmemobj++/array.hpp"
49 #include "libpmemobj++/string.hpp"
50 #include "libpmemobj++/vector.hpp"
51
52 /**
53 * Value - type of the value stored in hashmap
54 * N - number of buckets in hashmap
55 */
56 template <typename Value, std::size_t N>
57 class simple_kv {
58 private:
59 using key_type = pmem::obj::string;
60 using bucket_type = pmem::obj::vector<
61 std::pair<key_type, std::size_t>>;
62 using bucket_array_type = pmem::obj::array<bucket_type, N>;
63 using value_vector = pmem::obj::vector<Value>;
64
65 bucket_array_type buckets;
66 value_vector values;
67
68 public:
69 simple_kv() = default;
70
71 const Value &
72 get(const std::string &key) const
73 {
74 auto index = std::hash<std::string>{}(key) % N;
75
76 for (const auto &e : buckets[index]) {
77 if (e.first == key)
78 return values[e.second];
79 }
80
81 throw std::out_of_range("no entry in simplekv");
82 }
83
84 void
85 put(const std::string &key, const Value &val)
86 {
87 auto index = std::hash<std::string>{}(key) % N;
88
89 /* get pool on which this simple_kv resides */
90 auto pop = pmem::obj::pool_by_vptr(this);
91
92 /* search for element with specified key - if found
93 * update its value in a transaction*/
94 for (const auto &e : buckets[index]) {
95 if (e.first == key) {
96 pmem::obj::transaction::run(
97 pop, [&] { values[e.second] = val; });
98
99 return;
100 }
101 }
102
103 /* if there is no element with specified key, insert
104 * new value to the end of values vector and put
105 * reference in proper bucket */
106 pmem::obj::transaction::run(pop, [&] {
107 values.emplace_back(val);
108 buckets[index].emplace_back(key, values.size() - 1);
109 });
110 }
111 };- 第58-66行: 将hash map的布局定义为buckets 的pmem::obj::array数组,其中每个bucket是键和索引对的pmem::obj::vector,pmem::obj::vector包含值。bucket条目中的索引总是指定存储在单独vector中的实际值的位置。为了快照优化,该值不会保存在bucket中的键旁边。当获取对pmem::obj::vector中某个元素的非常量引用时,该元素总是快照的。为了避免快照不必要的数据,例如,如果键是不可变的,我们将键和值拆分为单独的vector。这也有助于在一个事务中更新多个值。回想一下“写时拷贝和版本控制”部分中的讨论。结果可能是在一个vector中彼此相邻,并且可以有更少的更大区域进行快照;
- 第74行: 使用标准库特性计算表中的哈希;
- 第76-79行: 通过遍历索引下表中存储的所有buckets,搜索具有指定键的条目。注意,e是对键值对的常量引用。由于libpmemobj-cpp容器的工作方式,与非常量引用相比,这对性能有积极影响;获取非常量引用需要快照,而常量引用不需要快照;
- 第90行: 获取pmemobj pool对象的实例,该对象用于管理数据结构所在的持久内存池;
- 第94-95行: 通过迭代指定bucket中的所有条目来查找值在值vector中的位置;
- 第96-98行: 如果找到具有指定键的元素,请使用事务更新其值;
- 第106-109行: 如果没有具有指定键的元素,则在值vector中插入一个值,并将对该值的引用放在适当的bucket中;即create key,index pair。这两个操作必须在单个原子事务中完成,因为我们希望它们要么都成功或要么都失败。
11.2.2 事务哈希表和选择性持久化
此示例演示如何通过将某些数据移出持久内存来修改持久数据结构(哈希表)。清单11-5所示的数据结构是清单11-4中哈希表的修改版本,包含了这个哈希表设计的实现。这里我们只存储键vector和值vector在持久内存中。在应用程序启动时,我们构建bucket并将其存储在易失性内存中,以便在运行时进行更快的处理。最显著的性能提升将出现在get()方法中。
Listing 11-5. Implementation of hash table with transactions and selective persistence
40 #include <array>
41 #include <functional>
42 #include <libpmemobj++/p.hpp>
43 #include <libpmemobj++/persistent_ptr.hpp>
44 #include <libpmemobj++/pext.hpp>
45 #include <libpmemobj++/pool.hpp>
46 #include <libpmemobj++/transaction.hpp>
47 #include <libpmemobj++/utils.hpp>
48 #include <stdexcept>
49 #include <string>
50 #include <vector>
51
52 #include "libpmemobj++/array.hpp"
53 #include "libpmemobj++/string.hpp"
54 #include "libpmemobj++/vector.hpp"
55
56 template <typename Value, std::size_t N>
57 struct simple_kv_persistent;
58
59 /**
60 * This class is runtime wrapper for simple_kv_peristent.
61 * Value - type of the value stored in hashmap
62 * N - number of buckets in hashmap
63 */
64 template <typename Value, std::size_t N>
65 class simple_kv_runtime {
66 private:
67 using volatile_key_type = std::string;
68 using bucket_entry_type = std::pair<volatile_key_type, std::size_t>;
69 using bucket_type = std::vector<bucket_entry_type>;
70 using bucket_array_type = std::array<bucket_type, N>;
71
72 bucket_array_type buckets;
73 simple_kv_persistent<Value, N> *data;
74
75 public:
76 simple_kv_runtime(simple_kv_persistent<Value, N> *data)
77 {
78 this->data = data;
79
80 for (std::size_t i = 0; i < data->values.size(); i++) {
81 auto volatile_key = std::string(data->keys[i].c_str(),
82 data->keys[i].size());
83
84 auto index = std::hash<std::string>{}(volatile_key)%N;
85 buckets[index].emplace_back(
86 bucket_entry_type{volatile_key, i});
87 }
88 }
89
90 const Value &
91 get(const std::string &key) const
92 {
93 auto index = std::hash<std::string>{}(key) % N;
94
95 for (const auto &e : buckets[index]) {
96 if (e.first == key)
97 return data->values[e.second];
98 }
99
100 throw std::out_of_range("no entry in simplekv");
101 }
102
103 void
104 put(const std::string &key, const Value &val)
105 {
106 auto index = std::hash<std::string>{}(key) % N;
107
108 /* get pool on which persistent data resides */
109 auto pop = pmem::obj::pool_by_vptr(data);
110
111 /* search for element with specified key - if found
112 * update its value in a transaction */
113 for (const auto &e : buckets[index]) {
114 if (e.first == key) {
115 pmem::obj::transaction::run(pop, [&] {
116 data->values[e.second] = val;
117 });
118
119 return;
120 }
121 }
122
123 /* if there is no element with specified key, insert new value
124 * to the end of values vector and key to keys vector
125 * in a transaction */
126 pmem::obj::transaction::run(pop, [&] {
127 data->values.emplace_back(val);
128 data->keys.emplace_back(key);
129 });
130
131 buckets[index].emplace_back(key, data->values.size() - 1);
132 }
133 };
134
135 /**
136 * Class which is stored on persistent memory.
137 * Value - type of the value stored in hashmap
138 * N - number of buckets in hashmap
139 */
140 template <typename Value, std::size_t N>
141 struct simple_kv_persistent {
142 using key_type = pmem::obj::string;
143 using value_vector = pmem::obj::vector<Value>;
144 using key_vector = pmem::obj::vector<key_type>;
145
146 /* values and keys are stored in separate vectors to optimize
147 * snapshotting. If they were stored as a pair in single vector
148 * entire pair would have to be snapshotted in case of value update */
149 value_vector values;
150 key_vector keys;
151
152 simple_kv_runtime<Value, N>
153 get_runtime()
154 {
155 return simple_kv_runtime<Value, N>(this);
156 }
157 };- 第67行: 定义了驻留在易失性存储器中的数据类型。这些类型与“事务哈希表”中持久版本中使用的类型非常相似,唯一的区别是这里我们使用std容器而不是pmem::obj;
- 第72行: 声明volatile buckets数组;
- 第73行: 声明指向持久数据的指针(simple_kv_ persistent结构);
- 第75-88行: 在simple_kv_runtime构造函数中,我们通过迭代持久内存中的键和值来重建bucket的数组。在易失性存储器中,我们将两个键存储在持久性存储器中,这两个键是持久性数据的副本和值vector的索引;
- 第90-101行: get() 函数在volatile bucket数组中查找元素引用。当我们在第97行读取实际值时,只有一个对持久内存的引用;
- 第113-121行: 与get()函数类似,我们使用volatile数据结构搜索元素,当找到时,在事务中更新其值;
- 第126-129行: 当哈希表中没有指定键的元素时,我们在一个事务中将值和键插入到持久内存中各自的vectors中;
- 第131行: 在将数据插入到持久内存之后,我们更新volatile数据结构的状态。注意,这个操作不一定是原子的。如果程序崩溃,bucket数组将在启动时重建;
- 第149-150行: 定义持久数据的布局。键和值存储在各自的pmem::obj::vector中。
- 第153-156行: 定义了一个函数,它返回这个哈希表的运行时对象。
11.2.3 带有版本控制的有序数组
本节概述了将元素插入有序数组并保持元素顺序的算法。该算法利用版本控制技术保证数据的一致性。
首先,我们描述有序数组的布局。图11-2和清单11-6显示了有两个元素数组和两个不同大小的字段。另外,一个当前字段存储有关当前使用的数组和大小变量的信息。

Listing 11-6. Sorted array layout
41 template <typename Value, uint64_t slots>
42 struct entries_t {
43 Value entries[slots];
44 size_t size;
45 };
46
47 template <typename Value, uint64_t slots>
48 class array {
49 public:
50 void insert(pmem::obj::pool_base &pop, const Value &);
51 void insert_element(pmem::obj::pool_base &pop, const Value&);
52
53 entries_t<Value, slots> v[2];
54 uint32_t current;
55 };- 第41-45行: 定义了helper结构,它由一个索引数组和一个大小组成;
- 第53行: 定义了entries_t结构的两个元素数组。entries_t保存元素数组(entries数组)和节点中的元素数作为size变量;
- 第54行: 此变量决定使用第53行中的哪个条目结构。它只能是0或1。图11-2显示了当前等于0并指向v数组的第一个元素的情况。
为了理解为什么我们需要两个版本的entries_t结构和一个current字段,图11-3显示了insert操作的工作原理,相应的伪代码如清单11-7所示。
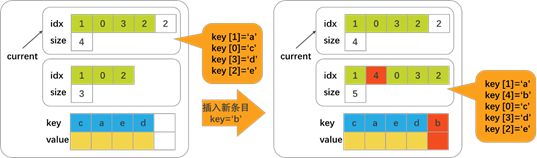
Listing 11-7. Pseudocode of a sorted tree insert operation
57 template <typename Value, uint64_t slots>
58 void array<Value, slots>::insert_element(pmem::obj::pool_base &pop,
59 const Value &entry) {
60 auto &working_copy = v[1 - current];
61 auto &consistent_copy = v[current];
62
63 auto consistent_insert_position = std::lower_bound(
64 std::begin(consistent_copy.entries),
65 std::begin(consistent_copy.entries) +
66 consistent_copy.size, entry);
67 auto working_insert_position =
68 std::begin(working_copy.entries) + std::distance(std::begin(consistent_copy.entries),
69 consistent_insert_position);
70
71 std::copy(std::begin(consistent_copy.entries),
72 consistent_insert_position,
73 std::begin(working_copy.entries));
74
75 *working_insert_position = entry;
76
77 std::copy(consistent_insert_position,
78 std::begin(consistent_copy.entries) + consistent_copy.size,
79 working_insert_position + 1);
80
81 working_copy.size = consistent_copy.size + 1;
82 }
83
84 template <typename V, uint64_t s>
85 void array<V,s>::insert(pmem::obj::pool_base &pop,
86 const Value &entry){
87 insert_element(pop, entry);
88 pop.persist(&(v[1 - current]), sizeof(entries_t<Value, slots>));
89
90 current = 1 - current;
91 pop.persist(¤t, sizeof(current));
92 }- 第60-61行: 定义对条目数组当前版本和工作版本的引用;
- 第63行: 找到当前数组中应该插入条目的位置;
- 第6行:为工作数组创建迭代器;
- 第71行: 将当前数组的一部分复制到工作数组(从当前数组的开头到插入新元素的位置);
- 第75行: 在工作数组中插入一个条目;
- 第77行: 将当前数组中的剩余元素复制到刚刚插入的元素之后的工作数组中;
- 第81行: 对于插入的元素,我们将工作数组的大小更新为当前数组的大小加上1;
- 第87-88行: 插入一个元素并持久化整个v[1-current]元素;
- 第90-91行: 更新current值并保存它。
让我们分析一下这种方法是否保证了数据的一致性。在第一步中,我们将元素从原始数组复制到当前未使用的数组中,插入新元素,并将其持久化,以确保数据进入持久化域。persist调用还确保下一个操作(更新当前值)不会在前面的任何存储之前重新排序。因此,在发出更新当前字段的指令之前或之后的任何中断都不会损坏数据,因为current变量始终指向有效版本。
对插入操作使用版本控制的内存开销等于条目数组和current字段的大小。在时间开销方面,我们只使用了两个persist操作。
11.3 本章小结
本章介绍如何设计持久内存的数据结构,并考虑其特性和功能。我们了讨论碎片化以及为什么在持久性内存的情况下会出现问题。我们还提出了几种保证数据一致性的不同方法;使用事务是最简单、最不易出错的方法。其他方法,如写时拷贝或版本控制,可以执行得更好,但它们很难正确实现。




