13 真实应用启用持久内存
本章将第四章(及其他章节)的理论转化为实践。我们将展示应用程序如何通过构建持久内存感知数据库存储引擎来利用持久内存。我们使用MariaDB(https://mariadb.org/),一个流行的开源数据库,因为它提供了一个可插拔的存储引擎模型。该完整的存储引擎目的不是用于生产,也没有实现生产质量存储引擎应该具备的所有功能。我们只实现了基本功能,以演示如何使用知名数据库开始持久内存编程。其目的是为您提供一种更实际的持久内存编程方法,以便您可以在自己的应用程序中启用持久内存功能。我们的存储引擎作为可选练习留给您完成。这样做将为MariaDB、MySQL创建一个新的持久内存存储引擎、Percona Server、其他衍生产品。您还可以选择修改现有的MySQL数据库存储引擎以添加持久内存功能,或者选择完全不同的数据库。
我们假设您熟悉前面介绍持久内存编程模型和持久内存开发工具包(PMDK)基本原理的章节。在本章中,我们从第8章使用C++和libpmemobj-cpp来实现我们的存储引擎。如果您不是C++开发人员,您仍然会发现此信息是有用的,因为基本原则适用于其他语言和应用程序。
持久内存感知数据库存储引擎完整的源码见:
https://github.com/pmem/pmdk-examples/tree/master/pmem-mariadb.
13.1 数据库示例
现有的大量应用程序可以通过多种方式进行分类。在本章中,我们将从公共组件的角度探讨应用程序,包括接口、业务层和存储。接口与用户交互,业务层是实现应用程序逻辑的层,存储是应用程序保存和处理数据的地方。
今天有这么多的应用程序可供使用,在本书中选择一个能满足我们所有或大部分需求的应用程序是很困难的。我们选择使用数据库作为示例,因为统一的数据访问方式是许多应用程序的共同特征。
13.2 不同的持久内存启用方式
持久内存主要优点包括:
- 它提供的访问延迟低于flash ssd;
- 它的吞吐量高于NAND存储设备;
- 对数据的实时访问允许超高速访问大型数据集;
- 断电后,数据仍保存在存储器中。
持久内存可以通过多种方式使用,为许多应用程序提供较低的延迟:
- 内存数据库:内存数据库可以利用持久内存的更大容量,并显著减少重启时间。一旦数据库内存映射索引、表和其他文件,就可以立即访问数据。这避免了传统上从磁盘读取数据并在访问或处理数据之前将其分页到内存的冗长启动时间;
- 欺诈检测:金融机构和保险公司可以对数百万条记录执行实时数据分析,以检测欺诈交易;
- 网络威胁分析:企业可以快速发现并防御日益增长的网络威胁;
- 网络规模个性化:企业可以通过返回相关内容和广告来定制在线用户体验,从而提高用户点击率,增加电子商务收入机会;
- 金融交易:金融交易应用程序可以快速处理和执行金融交易,使它们获得竞争优势,创造更高的收入机会;
- 物联网(IoT):更快的吸收采集的数据和实时处理巨大的数据集减少了价值实现的时间;
- 内容交付网络(CDN):CDN是一个高度分布式的边缘服务器网络,战略布局在全球各地,目的是向用户快速交付数字内容。有了内存容量,每个CDN节点都可以缓存更多的数据并减少服务器的总数,同时网络可以可靠地将低延迟数据传递给客户端。如果CDN缓存被持久化,则节点可以使用热缓存重新启动,并仅同步在脱离群集时丢失的数据。
13.3 开发持久内存感知的MariaDB存储引擎
这里开发的存储引擎达不到生产可用的质量,并且没有实现大多数数据库管理员所期望的所有功能。为了演示前面描述的概念,我们将示例保持简单,实现了table create()、open()和close()操作以及INSERT、UPDATE、DELETE和SELECT SQL操作。由于存储引擎的功能在没有索引的情况下非常有限,因此我们包括一个使用易失性内存的简单索引系统,以提供对驻留在持久性内存中的数据的更快访问。
尽管MariaDB有许多存储引擎,我们可以在这些引擎的基础上添加持久内存,但在本章中,我们还是选择从头开始构建一个新的存储引擎。为了进一步了解MariaDB存储引擎API以及存储引擎如何工作,我们建议阅读MariaDB“Storage Engine Development”文档(https:// mariadb.com/kb/en/library/storage-engines-storage-engine-development/)。由于MariaDB是基于MySQL的,您还可以参考MySQL的“Writing a Custom Storage Engine”文档(https://dev.mysql.com/doc/internals/en/custom- engine.html)查找从头开始创建引擎的所有信息。
13.3.1 理解存储层
MariaDB为存储引擎提供了一个可插入的体系结构,使开发和部署新的存储引擎更加容易。可插入的存储引擎体系结构还可以创建新的存储引擎,并将它们添加到正在运行的MariaDB服务器中,而无需重新编译服务器本身。存储引擎为MariaDB提供数据存储和索引管理。MariaDB服务器通过定义良好的API与存储引擎通信。
在我们的代码中,我们使用持久内存开发工具包(PMDK)中的libpmemobj库实现了一个可插入的、支持持久内存的MariaDB存储引擎原型。
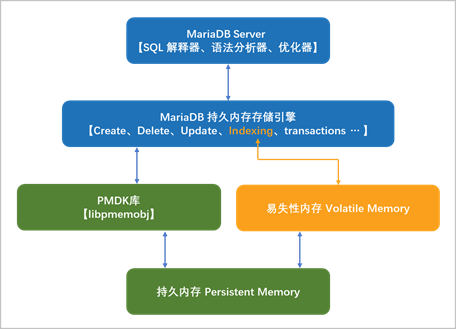
图13-1显示了存储引擎如何与libpmemobj通信以管理存储在持久内存中的数据。库用于将持久内存池转换为灵活的对象存储。
13.3.2 创建存储引擎类
这里描述的存储引擎的实现是单线程的,以支持单个会话、单个用户和单个表请求。多线程实现会分散本章的重点。第14章更详细地讨论了并发性,MariaDB服务器通过一个定义良好的处理程序接口与存储引擎通信,该接口包括handlerton,handlerton是一个连接到表处理程序的单例处理程序。handlerton定义存储引擎并包含指向应用于持久内存存储引擎的方法的指针。
存储引擎需要支持的第一个方法是启用对新处理程序实例的调用,如清单13-1所示。
Listing 13-1. ha_pmdk.cc – Creating a new handler instance
117 static handler *pmdk_create_handler(handlerton *hton,
118 TABLE_SHARE *table,
119 MEM_ROOT *mem_root);
120
121 handlerton *pmdk_hton;创建处理程序实例时,MariaDB服务器向处理程序发送命令,以执行数据存储和检索任务,如打开表、操作行、管理索引和事务。当处理程序被实例化时,第一个必需的操作是打开表。由于存储引擎是单用户单线程实现,因此只创建一个处理程序实例。
还实现了各种handler方法;它们作为一个整体应用于存储引擎,而不是像create()和open()这样按表工作。此类方法的一些示例包括处理提交和回滚的事务方法,如清单13-2所示。
Listing 13-2. ha_pmdk.cc – Handler methods including transactions, rollback, etc
209 static int pmdk_init_func(void *p)
210 {
...
213 pmdk_hton= (handlerton *)p;
214 pmdk_hton->state= SHOW_OPTION_YES;
215 pmdk_hton->create= pmdk_create_handler;
216 pmdk_hton->flags= HTON_CAN_RECREATE;
217 pmdk_hton->tablefile_extensions= ha_pmdk_exts;
218
219 pmdk_hton->commit= pmdk_commit;
220 pmdk_hton->rollback= pmdk_rollback;
...
223 }在handler类中定义的抽象方法是用来处理持久内存的。持久内存中对象的内部表示是使用单个链表(SLL)创建的。这个内部表示非常有助于遍历记录以提高性能。
为了执行各种操作并更快、更容易地访问数据,我们使用清单13-3所示的简单行结构将指向持久内存的指针和相关字段值保存在缓冲区中。
Listing 13-3. ha_pmdk.h – A simple data structure to store data in a single linked list
71 struct row {
72 persistent_ptr<row> next;
73 uchar buf[];
74 };13.3.3 创建数据库表
create()方法用于创建表。此方法使用libpmemobj在持久内存中创建所有必需的文件。如清单13-4所示,我们使用pmemobj_create()方法为每个表创建一个新的pmemobj类型池;该方法使用给定的总池大小创建一个事务对象存储。表是以.obj扩展名的形式创建的。
Listing 13-4. Creating a table method
1247 int ha_pmdk::create(const char *name, TABLE *table_arg,
1248 HA_CREATE_INFO *create_info)
1249 {
1250
1251 char path[MAX_PATH_LEN];
1252 DBUG_ENTER("ha_pmdk::create");
1253 DBUG_PRINT("info", ("create"));
1254
1255 snprintf(path, MAX_PATH_LEN, "%s%s", name, PMEMOBJ_EXT);
1256 PMEMobjpool *pop = pmemobj_create(path, name,PMEMOBJ_MIN_POOL, S_IRWXU);
1257 if (pop == NULL) {
1258 DBUG_PRINT("info", ("failed : %s error number : %d",path,errCodeMap[errno]));
1259 DBUG_RETURN(errCodeMap[errno]);
1260 }
1261 DBUG_PRINT("info", ("Success"));
1262 pmemobj_close(pop);
1263
1264 DBUG_RETURN(0);
1265 }13.3.4 打开数据库表
在对表执行任何读或写操作之前,MariaDB服务器调用open()方法来打开数据和索引表。此方法在存储引擎启动时打开与持久内存存储引擎关联的所有命名表。添加了一个新的表类变量objtab来保存PMEMobjpool。要打开的表的名称由MariaDB服务器提供。在服务器启动时,使用loadIndexTableFromPersistentMemory()函数调用open()函数填充易失性内存中的索引容器。
libpmemobj中的pmemobj_open()函数用于打开现有的对象存储内存池(请参见清单13-5)。如果触发了任何读/写操作,则在创建表时也会打开表。
Listing 13-5. ha_pmdk.cc – Opening a database table
290 int ha_pmdk::open(const char *name, int mode, uint test_if_locked)
291 {
...
302 objtab = pmemobj_open(path, name);
303 if (objtab == NULL)
304 DBUG_RETURN(errCodeMap[errno]);
305
306 proot = pmemobj_root(objtab, sizeof (root));
307 // update the MAP when start occured
308 loadIndexTableFromPersistentMemory();
...
310 }一旦存储引擎启动并运行,我们就可以开始向其中插入数据。但是我们首先必须实现INSERT、UPDATE、DELETE和SELECT操作。
13.3.5 关闭数据库表
当服务器处理完一个表时,它调用closeTable()方法来使用pmemobj_close()关闭文件并释放任何其他资源(参见清单13-6)。pmemobj_close()函数关闭objtab指示的内存池并删除内存池句柄。
Listing 13-6. ha_pmdk.cc – Closing a database table
376 int ha_pmdk::close(void)
377 {
378 DBUG_ENTER("ha_pmdk::close");
379 DBUG_PRINT("info", ("close"));
380
381 pmemobj_close(objtab);
382 objtab = NULL;
383
384 DBUG_RETURN(0);
385 }13.3.6 插入操作
INSERT操作在write_row()方法中实现,如清单13-7所示。在插入过程中,行对象保持在单个链接列表中。如果对表进行了索引,则在持久化操作成功完成后,将用新的行对象更新易失性内存中的索引表容器。write_row()是一个重要的方法,因为除了将持久池存储分配给行之外,它还用于填充索引容器。pmemobj_tx_alloc()用于插入。write_row()以事务方式分配指定大小和类型的新对象。
Listing 13-7. ha_pmdk.cc – Closing a database table
417 int ha_pmdk::write_row(uchar *buf)
418 {
...
421 int err = 0;
422
423 if (isPrimaryKey() == true)
424 DBUG_RETURN(HA_ERR_FOUND_DUPP_KEY);
425
426 persistent_ptr<row> row;
427 TX_BEGIN(objtab) {
428 row = pmemobj_tx_alloc(sizeof (row) + table->s->reclength, 0);
429 memcpy(row->buf, buf, table->s->reclength);
430 row->next = proot->rows;
431 proot->rows = row;
432 } TX_ONABORT {
433 DBUG_PRINT("info", ("write_row_abort errno :%d ",errno));
434 err = errno;
435 } TX_END
436 stats.records++;
437
438 for (Field **field = table->field; *field; field++) {
439 if ((*field)->key_start.to_ulonglong() >= 1) {
440 std::string convertedKey = IdentifyTypeAndConvertToString((*fie ld)->ptr, (*field)->type(),(*field)->key_length(),1);
441 insertRowIntoIndexTable(*field, convertedKey, row);
442 }
443 }
444 DBUG_RETURN(err);
445 }在每次插入操作中,都会检查字段值是否存在重复项。使用isPrimaryKey()函数(第423行)检查表中的主键字段。如果密钥是重复的,则返回HA_ERR_FOUND_DUPP_KEY错误。isPrimaryKey()在清单13-8中实现。
Listing 13-8. ha_pmdk.cc – Checking for duplicate primary keys
462 bool ha_pmdk::isPrimaryKey(void)
463 {
464 bool ret = false;
465 database *db = database::getInstance();
466 table_ *tab;
467 key *k;
468 for (unsigned int i= 0; i < table->s->keys; i++) {
469 KEY* key_info = &table->key_info[i];
470 if (memcmp("PRIMARY",key_info->name.str,sizeof("PRIMARY"))==0) {
471 Field *field = key_info->key_part->field;
472 std::string convertedKey = IdentifyTypeAndConvertToString (field->ptr, field->type(),field->key_length(),1);
473 if (db->getTable(table->s->table_name.str, &tab)) {
474 if (tab->getKeys(field->field_name.str, &k)) {
475 if (k->verifyKey(convertedKey)) {
476 ret = true;
477 break;
478 }
479 }
480 }
481 }
482 }
483 return ret;
484 }13.3.7 更新操作
服务器通过执行rnd_init()或index_init()表扫描来执行UPDATE语句,直到在调用update_row()方法之前在UPDATE语句的WHERE子句中找到与键值匹配的行为止。如果表是索引表,则此操作成功后还会更新索引容器。在清单13-9中定义的update_row()方法中,old_data字段将包含上一行记录,而new_data将包含新数据。
Listing 13-9. ha_pmdk.cc – Updating existing row data
506 int ha_pmdk::update_row(const uchar *old_data, const uchar *new_data)
507 {
...
540 if (k->verifyKey(key_str))
541 k->updateRow(key_str, field_str);
...
551 if (current)
552 memcpy(current->buf, new_data, table->s->reclength);
...
索引表也使用updateRow()方法更新,如清单13-10所示。
Listing 13-10. ha_pmdk.cc – Updating existing row data
1363 bool key::updateRow(const std::string oldStr, const std::string newStr)
1364 {
...
1366 persistent_ptr<row> row_;
1367 bool ret = false;
1368 rowItr matchingEleIt = getCurrent();
1369
1370 if (matchingEleIt->first == oldStr) {
1371 row_ = matchingEleIt->second;
1372 std::pair<const std::string, persistent_ptr<row> > r(newStr, row_);
1373 rows.erase(matchingEleIt);
1374 rows.insert(r);
1375 ret = true;
1376 }
1377 DBUG_RETURN(ret);
1378 }13.3.8 删除操作
DELETE操作是使用delete_row()方法实现的。应考虑三种不同的情况:
- 从索引表中删除索引值;
- 从索引表中删除非索引值;
- 从非索引表中删除字段。
对于每个场景,调用不同的函数。当操作成功时,将从索引(如果表是索引表)和持久内存中删除该项。清单13-11显示了实现这三个场景的逻辑。
Listing 13-11. ha_pmdk.cc – Updating existing row data
594 int ha_pmdk::delete_row(const uchar *buf)
595 {
...
602 // Delete the field from non indexed table
603 if (active_index == 64 && table->s->keys ==0 ) {
604 if (current)
605 deleteNodeFromSLL();
606 } else if (active_index == 64 && table->s->keys !=0 ) { // Delete non indexed column field from indexed table
607 if (current) {
608 deleteRowFromAllIndexedColumns(current);
609 deleteNodeFromSLL();
610 }
611 } else { // Delete indexed column field from indexed table
612 database *db = database::getInstance();
613 table_ *tab;
614 key *k;
615 KEY_PART_INFO *key_part = table->key_info[active_index].key_part;
616 if (db->getTable(table->s->table_name.str, &tab)) {
617 if (tab->getKeys(key_part->field->field_name.str, &k)) {
618 rowItr currNode = k->getCurrent();
619 rowItr prevNode = std::prev(currNode);
620 if (searchNode(prevNode->second)) {
621 if (prevNode->second) {
622 deleteRowFromAllIndexedColumns(prevNode->second);
623 deleteNodeFromSLL();
624 }
625 }
626 }
627 }
628 }
629 stats.records--;
630
631 DBUG_RETURN(0);
632 }清单13-12显示了deleteRowFromAllIndexedColumns()函数如何使用deleteRow()方法从索引容器中删除值。
Listing 13-12. ha_pmdk.cc – Deletes an entry from the index containers
634 void ha_pmdk::deleteRowFromAllIndexedColumns(const persistent_ptr<row> &row) 635 {
...
643 if (db->getTable(table->s->table_name.str, &tab)) {
644 if (tab->getKeys(field->field_name.str, &k)) {
645 k->deleteRow(row);
646 }
...deleteNodeFromSLL() 使用libpmemobj事务从持久内存中的链表中删除对象,如清单13-13所示。
Listing 13-13. ha_pmdk.cc – Deletes an entry from the linked list using transactions
651 int ha_pmdk::deleteNodeFromSLL()
652 {
653 if (!prev) {
654 if (!current->next) { // When sll contains single node
655 TX_BEGIN(objtab) {
656 delete_persistent<row>(current);
657 proot->rows = nullptr;
658 } TX_END
659 } else { // When deleting the first node of sll
660 TX_BEGIN(objtab) {
661 delete_persistent<row>(current);
662 proot->rows = current->next;
663 current = nullptr;
664 } TX_END
665 }
666 } else {
667 if (!current->next) { // When deleting the last node of sll
668 prev->next = nullptr;
669 } else { // When deleting other nodes of sll
670 prev->next = current->next;
671 }
672 TX_BEGIN(objtab) {
673 delete_persistent<row>(current);
674 current = nullptr;
675 } TX_END
676 }
677 return 0;
678 }13.3.9 选择操作
SELECT是一种重要的操作,有多种方法都需要它。为SELECT操作实现的许多方法也被其他方法调用。rnd_init()方法用于准备对非索引表进行表扫描,重置指向表开头的计数器和指针。如果表是索引表,则MariaDB服务器调用index_init()方法。如清单13-14所示,指针被初始化。
Listing 13-14. ha_pmdk.cc – rnd_init() is called when the system wants the storage engine to do a table scan
869 int ha_pmdk::rnd_init(bool scan)
870 {
...
874 current=prev=NULL;
875 iter = proot->rows;
876 DBUG_RETURN(0);
877 }初始化表时,MariaDB服务器将调用rnd_next()、index_first()或index_read_map()方法,具体取决于表是否被索引。这些方法使用来自当前对象的数据填充缓冲区,并将迭代器更新为下一个值。对要扫描的每一行调用一次方法。清单13-15显示了如何用内部MariaDB格式的表行内容填充传递给函数的缓冲区。如果没有要读取的对象,则返回值必须是HA_ERR_END_OF_FILE。
Listing 13-15. ha_pmdk.cc – rnd_init() is called when the system wants the storage engine to do a table scan
902 int ha_pmdk::rnd_next(uchar *buf)
903 {
...
910 memcpy(buf, iter->buf, table->s->reclength);
911 if (current != NULL) {
912 prev = current;
913 }
914 current = iter;
915 iter = iter->next;
916
917 DBUG_RETURN(0);
918 }至此,我们实现了持久内存存储引擎的基本功能。我们鼓励您继续开发此存储引擎,以引入更多功能和特性。
13.4 本章小结
本章介绍了如何使用PMDK中的libpmemobj为流行的开源MariaDB数据库创建持久内存感知存储引擎。在应用程序中使用持久性内存可以在意外系统关闭时提供连续性,并通过将数据存储在靠近CPU的位置(可以以内存总线的速度访问)来提高性能。虽然数据库引擎通常使用内存缓存来提高性能(这需要时间来预热),但持久内存在应用程序启动时提供了立即预热的缓存。




