14 并发性和持久内存
本章讨论为持久内存构建多线程应用程序时需要了解的内容。我们假设您已经有多线程编程的经验,并且熟悉一些基本概念,如互斥锁、临界区、死锁、原子操作等等。
本章的第一节重点介绍了为持久内存构建多线程应用程序的常见实用解决方案。我们描述了持久内存开发工具包(PMDK)事务库(如libpmemobj和libpmemobj-cpp)在并发执行方面的局限性。我们演示了一些简单的示例,这些示例对于易失性内存是正确的,但是在事务中止或进程崩溃的情况下,会导致持久性内存上的数据不一致问题。我们还讨论了为什么常规互斥不能在持久内存中像在易失性内存中那样放置,并引入了持久死锁术语。最后,我们描述了为持久内存构建无锁算法的挑战,并继续讨论前面章节中的可见性与持久性。
第二部分演示了为持久内存设计并发数据结构的方法。在发布的时候,我们有两个并发关联C++数据结构,用于持久内存-并发哈希映射和并发映射。我们将在本章中讨论这两种实现。
所有代码示例都是在C++中使用第8章中描述的libpmemobj-cpp库实现的。而在本章中,我们通常引用libpmemobj,因为它实现了这些特征,而libpmemobj-cpp只是它的一个C++扩展包装器。这些概念是通用的,可以应用于任何编程语言。
14.1 事务和多线程
在计算机科学中,ACID(原子性、一致性、隔离性和持久性)是一组事务的属性,旨在出现错误、电源故障和进程异常终止时保证数据的有效性和一致性。第7章介绍了PMDK事务及其ACID属性。本章重点讨论多线程程序与持久内存的关联性。后面会在第16章提供对libpmemobj事务内部的一些深入了解。
清单14-1中的小程序显示存储在根对象中的计数器由多个线程并发递增。程序打开持久内存池并打印计数器的值。然后它运行十个线程,每个线程都调用increment() 函数。所有线程成功完成后,程序将打印计数器的最终值。
Listing 14-1. Example to demonstrate that PMDK transactions do not automatically support isolation
41 using namespace std;
42 namespace pobj = pmem::obj;
43
44 struct root {
45 pobj::p<int> counter;
46 };
47
48 using pop_type = pobj::pool<root>;
49
50 void increment(pop_type &pop) {
51 auto proot = pop.root();
52 pobj::transaction::run(pop, [&] {
53 proot->counter.get_rw() += 1;
54 });
55 }
56
57 int main(int argc, char *argv[]) {
58 pop_type pop =
59 pop_type::open("/pmemfs/file", "COUNTER_INC");
60
61 auto proot = pop.root();
62
63 cout << "Counter = " << proot->counter << endl;
64
65 std::vector<std::thread> workers;
66 workers.reserve(10);
67 for (int i = 0; i < 10; ++i) {
68 workers.emplace_back(increment, std::ref(pop));
69 }
70
71 for (int i = 0; i < 10; ++i) {
72 workers[i].join();
73 }
74
75 cout << "Counter = " << proot->counter << endl;
76
77 pop.close();
78 return 0;
79 }您可能希望清单14-1中的程序打印的最终计数器值是10。但是,PMDK事务不自动支持与ACID属性集的隔离。在当前事务隐式提交(其在第54行)更新之前,第53行的增量操作的结果对其他并发事务可见。也就是说,本例中发生了一个简单的数据竞争。当两个或多个线程可以访问共享数据,并且它们试图同时更改共享数据时,就会出现竞争条件。由于操作系统的线程调度算法可以随时在线程之间进行交换,因此应用程序无法知道线程尝试访问共享数据的顺序。因此,数据更改的结果取决于线程调度算法,也就是说,两个线程都在“竞相”访问/更改数据。
如果我们多次运行此示例,结果每次不同。我们可以尝试通过在计数器递增之前获取互斥锁来修复竞争条件,如清单14-2所示。
Listing 14-2. Example of incorrect synchronization inside a PMDK transaction
46 struct root {
47 pobj::mutex mtx;
48 pobj::p<int> counter;
49 };
50
51 using pop_type = pobj::pool<root>;
52
53 void increment(pop_type &pop) {
54 auto proot = pop.root();
55 pobj::transaction::run(pop, [&] {
56 std::unique_lock<pobj::mutex> lock(proot->mtx);
57 proot->counter.get_rw() += 1;
58 });
59 }- 第47行: 我们为root 数据结构加了mutex锁;
- 第56行: 在递增计数器值以避免竞争条件之前,我们在事务中获取了互斥锁。每个线程都会增加受互斥锁保护的关键部分内的计数器。
现在,如果我们多次运行这个示例,它总是将存储在持久内存中的计数器的值增加1。但我们还没有结束。不幸的是,清单14-2中的示例也是错误的,可能会导致持久内存上的数据不一致问题。如果没有事务中止,则该示例工作良好。但是,如果事务在释放锁之后、事务完成并成功地将其更新提交到持久内存之前中止,则其他线程可以读取可能导致数据不一致问题的计数器的缓存值。要理解这个问题,您需要知道libpmemobj事务在内部是如何工作的。目前,我们只讨论了解这一问题所需的必要细节,而将对交易及其实现的深入讨论留给第16章。
libpmemobj事务通过跟踪undo日志中的更改来保证原子性。在失败或事务中止的情况下,将从undo日志还原未提交更改的旧值。重要的是要知道undo日志是一个特定于线程的实体。这意味着每个线程都有自己的undo日志,该日志与其他线程的undo日志不同步。
图14-1说明了当我们调用清单14-2中的increment()函数时,事务内部发生的事情。为了便于说明,我们只描述两个线程。每个线程执行并发事务以增加在持久内存中分配的计数器的值。我们假设counter的初始值为0,第一个线程获取锁,而第二个线程等待锁。在critical部分中,第一个线程将counter的初始值添加到undo日志并递增它。当执行流离开lambda作用域,但事务尚未将更新提交到持久内存时,将释放互斥锁。这些更改将立即对第二个线程可见。执行用户提供的lambda之后,事务需要刷新对持久内存的所有更改,以将更改标记为已提交。同时,第二个线程将counter的当前值(现在是1)添加到其undo日志中并执行增量操作。此时,有两个未提交的事务。线程1的撤消日志包含counter=0,线程2的撤消日志包含counter=1。如果线程2提交其事务,而线程1由于某种原因(崩溃或中止)中止其事务,则计数器的错误值将从线程1的撤消日志中还原。
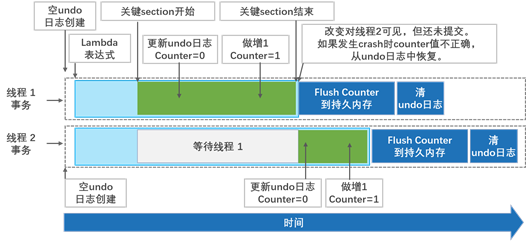
解决方案是保持互斥锁,直到事务完全提交,并且数据已成功刷新到持久内存。否则,一个事务所做的更改在被持久化和提交之前对并发事务可见。清单14-3演示了如何正确实现increment()函数。
Listing 14-3. Correct example for concurrent PMDK transaction
52 void increment(pop_type &pop) {
53 auto proot = pop.root();
54 pobj::transaction::run(pop, [&] {
55 proot->counter.get_rw() += 1;
56 }, proot->mtx);
57 }libpmemobj API允许我们指定在整个事务期间应该获取和持有的锁。在清单14-3示例中,我们将proot>mtx互斥对象作为第三个参数传递给run()方法。
14.2 持久内存上的Mutex锁
我们前面的示例使用pmem::obj::mutex作为根数据结构中mtx成员的类型,而不是标准模板库提供的常规std::mutex对象是驻留在持久内存中的根对象的成员。std::mutex类型不能用于持久内存,因为它可能导致持久死锁。
如果在保持互斥锁时发生应用程序崩溃,则会发生持久性死锁。当程序启动时,如果启动时没有释放或重新初始化互斥锁,则试图获取互斥锁的线程将永远等待。为了避免这种情况,libpmemobj提供驻留在持久内存中的同步原语。同步原语的主要特点是,每次打开持久对象存储池时,它们都会自动重新初始化。
对于C++开发人员来说,libpmemobj-cpp库提供了类似C++ 11的同步原语,见表14-1所示。
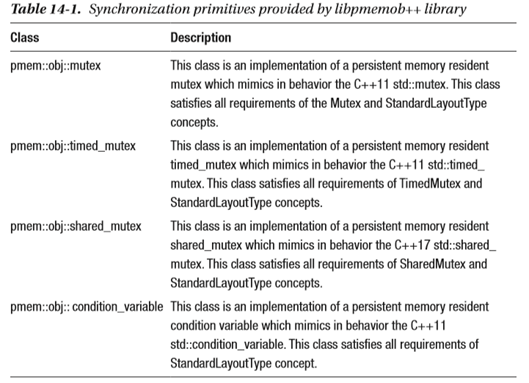
对于C开发人员,libpmemobj库提供了如表14-2所示的类似于pthread的同步原语。持久内存感知锁定实现基于标准POSIX线程库,并提供类似于标准pthread锁的语义。

这些方便的持久内存感知同步原语可用于C和C++开发人员。但是,如果开发人员想要使用更适合特定用例的自定义同步对象呢?如前所述,持久性内存感知同步原语的主要特点是,每次打开持久性内存池时,它们都会重新初始化。libpmemobj-cpp库提供了一种更通用的机制,可以在每次打开持久内存池时重新初始化任何用户提供的类型。
Libpmemobj-cpp提供了pmem::obj::v<T>类模板,该模板允许在持久数据结构中创建易失性字段。互斥对象在语义上是一个易失性实体,互斥对象的状态不应该在应用程序重新启动后继续存在。应用程序重新启动时,互斥对象应处于解锁状态。pmem::obj::v<T>类模板就是为此目的而设计的。清单14-4演示了如何将pmem::obj::v<T>类模板与持久内存上的std::mutex一起使用。
Listing 14-4. Example demonstrating usage of std::mutex on persistent memory
38 namespace pobj = pmem::obj;
39
40 struct root {
41 pobj::experimental::v<std::mutex> mtx;
42 };
43
44 using pop_type = pobj::pool<root>;
45
46 int main(int argc, char *argv[]) {
47 pop_type pop =
48 pop_type::open("/pmemfs/file", "MUTEX");
49
50 auto proot = pop.root();
51
52 proot->mtx.get().lock();
53
54 pop.close();
55 return 0;
56 }- 第41行:我们只将mtx对象存储在持久内存的根对象中;
- 第47-48行:打开布局名为“MUTEX”的持久内存池;
- 第50行:我们获得指向池中根数据结构的指针;
- 第52行:我们获取互斥;
- 第54-56行:关闭池子并退出程序。
如您所见,我们没有在main() 函数中显式地解除互斥锁。如果我们多次运行这个例子,main() 函数总是可以在第52行锁定互斥锁。这是因为pmem::obj::v<T>类模板隐式调用默认构造函数,该构造函数是包装的std::mutex对象类型。每次打开持久内存池时都会调用构造函数,这样就不会遇到已经获取锁的情况。
如果我们将第41行的mtx对象类型从pobj::experimental::v<std::mutex>更改为std::mutex并尝试再次运行程序,则该示例将在第52行的第二次运行期间挂起,因为mtx对象在第一次运行期间被锁定,并且我们从未释放它。
14.3 原子操作与持久内存
由于图14-1所述的原因,不能在PMDK事务中使用原子操作。在提交事务之前,事务内的原子操作所做的更改对其他并发线程可见。它在异常程序终止或事务中止的情况下强制出现数据不一致问题。考虑无锁算法,其中并发是通过原子更新内存中的状态来实现的。
14.3.1 无锁算法与持久内存
直觉地认为,无锁算法自然适合持久性内存。在无锁算法中,线程安全是通过一致状态之间的原子转换来实现的,这正是我们在持久内存中支持数据一致性所需要的。但这种假设并不总是正确的。
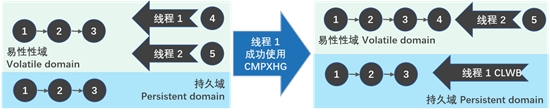
要理解无锁算法的问题,请记住,具有持久内存的系统通常将虚拟内存子系统分为两个域:volatile和persistent(如第2章所述)。原子操作的结果只能使用缓存一致性协议更新CPU缓存中的数据。除非调用显式flush操作,否则无法保证数据将被flush。CPU缓存仅包含在具有eADR支持的平台上的持久性域中。对于持久内存,这不是必需的。ADR是持久内存的最低平台需求,在这种情况下,CPU缓存不会在电源故障时被flush。
图14-2假设系统有ADR支持。该示例显示了对持久内存中单个链接列表的并发无锁插入操作。两个线程正在尝试使用比较和交换(CMPXCHG指令)操作和缓存flush操作(CLWB指令)将新节点插入到链接列表的尾部。假设线程1成功地完成了比较和交换,因此更改出现在易失性域中,并对第二个线程可见。此时,线程1可能被抢占(更改不会刷新到持久域),而线程2在节点4之后插入节点5并将其刷新到持久域。存在数据不一致的可能性,因为线程2基于线程1尚未持久化的数据执行更新。
14.4 适于持久内存的并发数据结构
本节描述libpmemobj-cpp库中可用的两个并发数据结构:pmem::obj::concurrent_map和pmem::obj::concurrent_hash_map。两者都是由键和值对的集合组成的关联数据结构,因此每个可能的键在集合中最多出现一次。它们之间的主要区别在于并发哈希映射是无序的,而并发映射是按键排序的。
在这个上下文中,我们定义concurrent是组织数据结构以供多个线程访问的方法。当多个线程可以同时调用数据结构的方法而不需要额外的同步时,这种数据结构可用于并行计算环境。
C++标准模板库(STL)数据结构可以被封装在粗粒度互斥中,这种互斥使它们只能在该容器上运行一个线程的一次访问操作是安全的,从而使它们对并发访问安全。然而,这种方法消除了并发性,从而限制了在性能关键代码中实现的并行加速。设计并发数据结构是一项具有挑战性的任务。当我们需要为持久内存开发并发数据结构并使其具有容错性时,困难就大大增加了。
pmem::obj::concurrent_map和pmem::obj::concurrent_hash_map结构的灵感来自“Intel Threading Building Blocks”(Intel TBB),提供了为易失性内存设计的这些并发数据结构的实现。您可以通过阅读《Pro TBB: C++ Parallel Programming with Threading Building Blocks book2》,以获得更多信息,并了解如何在应用程序中使用这些并发数据结构。免费电子版可从https://www.apress.com/gp/book/9781484243978。【已下载:2019_Book_ProTBB.pdf】
在我们的并发关联数据结构中,主要有三种方法:查找、插入和擦除/删除。我们描述了每种数据结构,重点介绍了这三种方法。
14.4.1 Concurrent Ordered Map
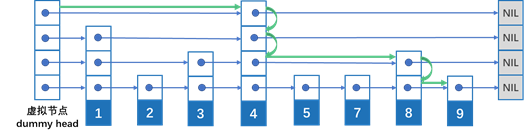
持久内存并发有序映射((pmem::obj::concurrent_map)的实现基于并发跳表skip list数据结构。Intel TBB提供tbb::concurrent_map,它是为易失性存储器设计的,我们将其用为持久性存储器端口的基线。并发跳表数据结构可以实现为无锁算法。但Intel选择了一个可证明正确的可伸缩并发跳表实现,该实现具有细粒度锁定,以简单性和可伸缩性相结合而著称。图14-3展示了跳表数据结构的基本思想。它是一个多层链表式的数据结构,底层是一个有序链表。每个较高的层充当以下列表的“快速通道”,并允许它在查找操作期间跳过元素。第一层中的一个元素出现在第一层+1中,具有一定的概率p(在我们的实现中p=1/2)。也就是说,特定高度节点的频率随高度呈指数下降。这样的属性允许它实现查找、插入和删除操作的O(log n)平均时间复杂性。O(log n)表示运行时间最多与“logn”成正比。你可以在维基百科上了解更多关于大O符号的信息https://en.wikipedia.org/wiki/ Big_O_notation。
对于pmem::obj::concurrent_map的实现,find和insert操作是线程安全的,可以与其他find和insert操作同时调用,而不需要额外的同步。
14.4.2 查找操作
因为find操作是非修改的,所以它不必处理数据一致性问题。目标元素的查找操作始终从最顶层开始。算法水平进行,直到下一个元素大于或等于目标。如果无法在当前级别上继续,则垂直向下拉到下一个较低的列表。图14-3说明了对于key=9的元素find操作是如何工作的。搜索从最高级别开始,然后立即从虚拟头节点转到键为4的节点,跳过键为1、2、3的节点。在key=4的节点上,搜索将向下放置两层,并转到key=8的节点。然后,它再向下放置一层,并前进到所期望的key=9的节点。
查找操作无需等待。也就是说,每个find操作只受算法执行的步骤数的限制。并且保证一个线程完成该操作,而不考虑其他线程的活动。当读取指向下一个节点的指针时,pmem::obj::concurrent_map的实现使用带有获取内存语义的原子加载。
14.4.3 插入操作
插入操作(如图14-4所示)采用细粒度的锁模式来保证线程安全,包括以下基本步骤,以便将key=7的新节点插入到列表中:
- 为新节点分配随机生成的高度;
- 找到插入新节点的位获取每个前置节点的锁,并检查后续节点是否未更改。如果后续节点已更改,则算法返回到步骤2。我们必须在每个级别上找到前一个和后一个节点;
- 获取每个前置节点的锁,并检查后续节点是否未更改。如果后续节点已更改,则算法返回到步骤2;
- 将新节点插入从底部开始的所有层。由于find操作是无锁的,我们必须使用带释放存储的内存语义原子地更新每层上的指针。
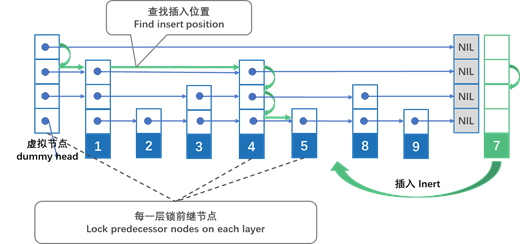
前面描述的算法是线程安全的,但不足以在持久内存上进行容错。如果程序在算法的第一步和第四步之间意外终止,则可能存在持久性内存泄漏。
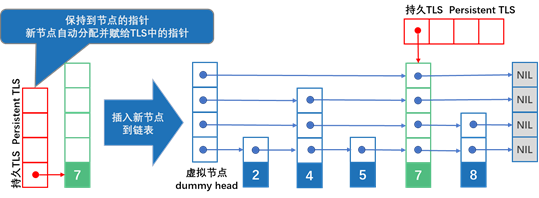
pmem::obj::concurrent_map的实现不使用事务来支持数据一致性,因为事务不支持隔离,通过不使用事务,可以获得更好的性能。对于这个链表数据结构,由于新分配的节点总是可访问的(以避免持久的内存泄漏),并且链表数据结构总是有效的,所以保持了数据一致性。为了支持这两个属性,使用了持久线程本地存储,它是并发跳过列表数据结构的一个成员。持久线程本地存储保证每个线程在持久内存中都有自己的位置,以便为新节点布置分配持久内存的结果。
图14-5说明了这种容错插入算法的方法。当一个线程分配一个新节点时,指向该节点的指针保存在持久线程本地存储中,并且可以通过这个持久线程本地存储访问该节点。然后,该算法使用前面描述的线程安全算法将新节点链接到所有层,从而将其插入跳表。最后,永久线程本地存储中的指针将被删除,因为现在可以通过跳表本身访问新节点。如果失败,一个特殊函数将遍历持久线程本地存储中的所有非零指针并完成插入操作。
14.4.4 擦除操作
pmem::obj::concurrent_map的擦除操作的实现不是线程安全的。这种方法不能同时调用concurrent ordered map的其他方法,因为这是一个内存回收问题,在没有垃圾收集器的C++中很难解决。有一种方法可以以线程安全的方式从跳表中逻辑地提取节点,但检测何时安全删除节点并不容易,因为其他线程可能一直在访问该节点。这有些可能的解决方案,例如危险指针,但这些会影响查找和插入操作的性能。
14.4.5 并发Hash Map
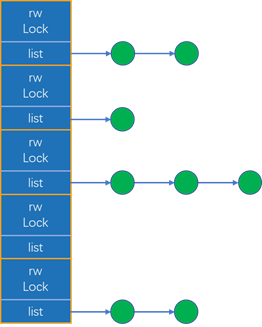
为永久内存设计的并发hash map基于Intel TBB中存在的tbb::concurrent_ hash_map。该实现基于并发哈希表算法,其中分配给存储桶的元素是基于从key计算出来的哈希值。除了并发的查找、插入和擦除操作外,该算法还采用了并发调整大小和按需对每个bucket重新进行哈希。
图14-6说明了并发哈希表的基本思想。哈希表由一个bucket数组组成,每个bucket由一个节点列表和一个读写锁组成,用于控制多个线程的并发访问。
Anton Malakhov. Per-bucket concurrent rehashing algorithms, 2015, arXiv:1509.02235v1; https://arxiv.org/ftp/arxiv/papers/1509/1509.02235.pdf.
14.4.6 查找操作
查找操作是一个只读事件,不会更改hash map状态。因此,在执行查找请求时保持数据一致性。find操作首先计算目标key的散列值,然后获取对应bucket的读锁。读锁保证在我们读取bucket时不会对其进行并发修改。在bucket中,find操作通过节点列表执行线性搜索。
14.4.7 插入操作
并发hash map的insert方法使用与并发跳表数据结构相同的技术来支持数据一致性。操作包括以下步骤:
- 分配新节点,并将指向新节点的指针分配给持久线程本地存储;
- 计算新节点的哈希值,并找到相应的bucket;
- 获取bucket的写锁;
- 通过将新节点链接到节点列表,将其插入bucket。因为只需要更新一个指针,所以不需要事务。因为只更新一个指针,所以不需要事务。
14.4.8 擦除操作
尽管擦除操作类似于插入(相反的操作),但其实现甚至比插入更简单。erase实现获取所需bucket的写锁,并使用事务从该bucket内的节点列表中移除相应的节点。
14.5 本章小结
尽管为持久性内存构建应用程序是一项具有挑战性的任务,但是当需要为持久性内存创建多线程应用程序时,这项任务会更加困难。当多个线程可以更新持久内存中的相同数据时,您需要在多线程环境中处理数据一致性。
如果您开发并发应用程序,我们鼓励您使用现有的库,这些库提供设计用于将数据存储在持久内存中的并发数据结构。只有当通用算法不适合您的需要时,您才应该开发自定义算法。参见第9章中描述的pmemkv中并发cmap和csmap引擎的实现,它们分别使用pmem::obj::concurrent_hash_map和pmem::obj::concurrent_map实现。
如果需要开发自定义多线程算法,请注意PMDK事务对并发执行的限制。本章说明事务不会自动提供开箱即用的隔离。在一个事务中所做的更改在提交之前对其他并发事务可见。如果算法需要,则需要实现额外的同步。我们还解释了在没有事务的情况下构建无锁算法时,不能在事务内部使用原子操作。如果您的平台不支持eADR,这是一项非常复杂的任务。




