17 可靠性、可用性和可服务性(RAS)
本章描述了为持久性内存设计的可靠性、可用性和可服务性(RAS)特性的高级体系结构。持久内存RAS特性被设计为应用使用持久内存时所需的特有错误处理策略。错误处理是程序整体可靠性的重要组成部分,它直接影响到应用程序的可用性。应用程序的错误处理策略影响应用程序可用于完成其工作的预期时间的百分比。
持久性内存供应商和平台供应商都将决定哪些RAS特性以及如何在最低的硬件级别上实现它们。一些常见的RAS特性被设计并记录在ACPI规范中,该规范由UEFI论坛维护和拥有(网址:https://uefi.org/)。在本章中,我们试图获得这些ACPI定义的RAS特性的一般视角,并在必要时引入特定于供应商的详细信息。
17.1 处理无法纠正的错误
服务器的主内存使用纠错码(ECC)进行保护。这是一种常见的硬件功能,可以自动更正由于瞬时硬件问题而发生的许多内存错误,如电源尖峰、软介质错误等。如果错误足够严重,损坏足够的位以致ECC无法更正;结果称为不可更正错误(UE)。
持久性内存中不可纠正的错误需要特殊的RAS处理,这与平台通常处理易失性内存不可纠正错误的方式不同。
持久性内存无法纠正的错误是持久性的。与易失性存储器不同,如果断电或应用程序崩溃并重新启动,则无法纠正的错误将保留在硬件上。这可能导致应用程序陷入无限循环,如:
- 应用程序启动;
- 读取内存地址;
- 遇到无法纠正的错误;
- 崩溃(或系统崩溃和重新启动);
- 从停止的位置开始并恢复操作;
- 对触发上次重新启动的同一内存地址执行读取;
- 崩溃(或系统崩溃和重新启动);
- …
- 无限重复直到手动干预。
操作系统和应用程序可能需要以三种主要方式了解并解决无法纠正的错误:
- 在运行时使用以前未检测到的无法纠正的错误时;
- 当运行时检测到未使用的不可纠正错误时;
- 减轻启动时检测到的不可纠正的内存位置时。
17.1.1 已使用不可纠正错误的处理
当在所请求的存储器地址上检测到不可纠正的错误时,数据中毒用于通知CPU所请求的数据具有不可纠正的错误。当硬件检测到一个不可纠正的内存错误时,它会将一个有害位和数据一起路由到CPU。对于Intel体系结构,当CPU检测到这个有害位时,它会向操作系统发送一个处理器中断信号,通知它这个错误。此信号称为机器检查异常(MCE)。然后,操作系统可以检查不可纠正的内存错误,确定软件是否可以恢复,并通过MCE处理程序执行恢复操作。通常,不可纠正的错误分为三类:
- 可能已损坏CPU的状态并需要系统重置;
- 可以运行期间由软件处理并恢复;
- 无需做任何处理。
操作系统供应商以不同的方式处理这个不可纠正的错误通知,但是它们都存在一些共同的元素。
以Linux为例,当操作系统接收到一个不可纠正错误的处理器中断时,它将使发生不可纠正错误的内存页脱机,并将该错误添加到包含已知不可纠正错误的区域列表中。这个已知的不可纠正错误的列表称为坏块列表。Linux还将标记包含不可纠正错误的页面,以便在该页面被回收供其他应用程序使用时清除。
PMDK库会自动检查操作系统中有不可纠正错误的页面列表,并防止应用程序打开包含错误的持久内存池。如果应用程序正在使用内存页,Linux将尝试使用SIGBUS机制终止该程序。
在此点上,应用程序开发人员可以决定如何处理此错误通知。处理不可纠正错误的最简单方法是让应用程序在获得SIGBUS时死掉,这样就不需要编写在运行时处理SIGBUS的复杂逻辑。一个替代方案是,应用在重新启动时,使用PMDK来检测持久内存池是否包含错误,并在初始化期间修复数据。对于许多应用程序,此修复可以简单地恢复为备份的数据无错误的副本。 图17-1显示了Linux如何处理应用程序使用的不可纠正(但不是致命)错误的简化序列图:

17.1.2 未使用不可纠正错误的处理
RAS特性被定义为通知软件在持久性存储介质上发现但尚未被软件使用的不可纠正的错误。此功能的目标是允许操作系统有机会脱机或清除具有已知不可纠正错误的页面,然后才能供应用程序使用。如果应用程序已在使用不可纠正错误的地址,则操作系统也可以选择将未使用的不可纠正错误通知该应用程序,或等待应用程序使用该错误。操作系统可能会选择等待应用程序从未尝试访问受影响的页,然后应用程序将该页返回到操作系统进行回收。此时,操作系统将清除或脱机无法纠正的错误。
未使用不可纠正错误的处理可以在不同的供应商平台上以不同的方式实现,但其核心始终是发现未使用的不可纠正错误的机制、向操作系统发出未使用的不可纠正错误的信号的机制和操作系统查询有关未使用的不可纠正的错误信息的机制。如图17-2所示,这三种机制协同工作,在运行时主动向操作系统通报所有发现的不可纠正错误。

17.1.3 巡逻擦洗/内存清理
巡逻擦洗Patrol scrub(也称为内存清理)是一个长期存在的RAS特性,用于易失性内存,也可以扩展到持久性内存。这是一个很好的例子,说明了平台如何在正常运行期间发现后台不可纠正的错误。巡逻擦洗是使用硬件引擎完成的,无论是在平台上还是在内存设备上,它都会生成对内存设备上的内存地址的请求。引擎以预定义的频率生成内存请求。如果有足够的时间,它最终将访问每个内存地址。巡逻擦洗生成请求的频率对内存设备的服务质量没有明显影响。
通过生成对内存地址的读取请求,巡逻擦洗器允许硬件有机会在内存地址上运行ECC,并在任何可纠正的错误变为不可纠正的错误之前进行纠正。或者,如果发现不可纠正的错误,巡逻擦洗可以触发硬件中断并通知其内存地址的软件层。
17.1.4 未使用的不可纠正内存错误持久内存根设备通知
ACPI规范描述了一种硬件通知软件未使用不可纠正错误的方法,称为未使用不可纠正内存-错误持久内存根设备通知(Unconsumed Uncorrectable Memory- Error Persistent Memory Root-Device Notification)。使用ACPI定义的框架,当检测到不可纠正的内存错误时,操作系统可以订阅平台通知。平台有责任接收来自持久性内存设备的关于检测到不可纠正错误的通知,并采取适当措施生成持久性内存根设备通知。在收到根设备通知后,操作系统可以使用现有的ACPI方法(如地址范围清理(ARS))来发现新创建的不可纠正内存错误的地址并采取适当的操作。
17.1.5 地址范围清理
地址范围清理(Address Range Scrub,简称ARS)是ACPI规范中定义的一种设备专用方法(_DSM)。特权软件可以在运行时调用ACPI-DSM(如ARS),以检索或扫描平台中所有持久内存的不可纠正内存错误位置。因为ARS是由平台实现的,所以每个供应商可能会以不同的方式实现某些功能。
ARS从调用者接受给定的系统地址范围,并像巡逻擦洗一样,检查该范围内的每个内存地址是否存在内存错误。当ARS完成时,给调用者一个给定范围内包含内存错误的内存地址列表。对每个存储器地址的检查可以由持久存储器硬件或平台本身来处理。与巡逻擦洗不同,ARS以非常高的频率检查每个内存地址。擦洗频率的增加可能会影响持久内存硬件的服务质量。因此,调用者可以选择性地调用ARS以返回前一个ARS的结果,有时称为短ARS。
传统上,操作系统以两种方式之一执行ARS,以便在启动后获得不可纠正错误的地址。在系统引导期间或在收到未使用的不可纠正内存错误根设备通知后,对所有可用的持久内存执行完全扫描。在这两种情况下,目的是在应用程序使用这些地址之前发现它们。
操作系统会将ARS返回的不可纠正错误列表与它们的不可纠正错误的持久列表进行比较。如果检测到新错误,则更新列表。此列表用于更高层的软件,如PMDK库。
17.1.6 清除不可纠正的错误
永久性存储器的不可纠正错误将在断电后继续存在,可能需要特殊处理才能从存储器地址中清除损坏的数据。当一个不可纠正的错误被清除时,请求的内存地址的数据被修改,错误被清除。由于硬件无法静默地修改应用程序数据,清除无法纠正的错误是软件的责任。清除不可纠正的错误是可选的,某些操作系统可能会选择仅包含内存错误的脱机内存页,而不是回收包含不可纠正错误的内存页。在某些操作系统中,特权应用程序可能有权清除无法纠正的错误。然而,操作系统却不需要提供这种权限【就可以执行清除】。
ACPI规范为操作系统定义了一个Clear Uncorrectable Error DSM,用于给平台发指令来清除不可纠正的错误。虽然持久内存编程是字节寻址的,但清除不可纠正的错误则不是。持久性存储器的不同供应商的具体实现可以指定由Clear Uncorrectable Error DSM指令清除的内存单元的对齐和大小。成功执行Clear Uncorrectable Error DSM命令后,还应更新内存错误的内部平台或操作系统列表。
17.2 设备健康
系统管理员可能希望在开始影响使用持久内存的应用程序的可用性之前,采取行动并缓解任何设备运行状况的问题。为此,操作系统或管理应用程序将希望发现持久内存设备运行状况的准确图像,以正确确定持久内存的可靠性。ACPI规范定义了一些与供应商无关的运行状况发现方法,但许多供应商实现了额外的持久性内存设备方法。许多特定于供应商的健康发现方法都是作为ACPI设备专有方法(DSM)实现的。如果应用程序直接调用ACPI方法,则应该注意服务质量的降低,因为在调用ACPI方法时,某些平台实现可能会影响内存交通。尽可能避免过度轮询设备运行状况方法。
在Linux上,ndctl实用程序可用于查询持久内存模块的设备运行状况。清单17-1显示了Intel Optane DC永久内存模块的输出示例。
Listing 17-1. Using ndctl to query the health of persistent memory modules
$ sudo ndctl list -DH -d nmem1
[
{
"dev":"nmem1",
"id":"8089-a2-1837-00000bb3",
"handle":17,
"phys_id":44,
"security":"disabled",
"health":{
"health_state":"ok",
"temperature_celsius":30.0,
"controller_temperature_celsius":30.0,
"spares_percentage":100,
"alarm_temperature":false,
"alarm_controller_temperature":false,
"alarm_spares":false,
"alarm_enabled_media_temperature":false,
"alarm_enabled_ctrl_temperature":false,
"alarm_enabled_spares":false,
"shutdown_state":"clean",
"shutdown_count":1
}
}
]ndctl还提供了一个监视命令和守护进程,用于连续监视系统持久内存模块的运行状况。有关所有可用选项的列表,请参阅ndctl监视器(1)手册页。使用此监视方法的示例包括:
示例1:将监视器作为守护进程运行,以监视总线“nfit_test.1”上的DIMMs
$ sudo ndctl monitor --bus=nfit_test.1 --daemon示例2:将监视器作为一个一次性命令运行,并将通知输出到/var/log/ndctl.log日志.
$ sudo ndctl monitor --log=/var/log/ndctl.log示例3:将监视器守护进程作为系统服务运行。
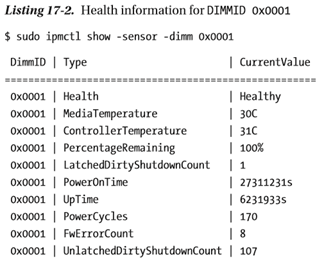
$ sudo systemctl start ndctl-monitor.service您可以使用永久内存设备的专有实用程序获得类似的信息。例如,可以在Linux和Windows*上使用ipmctl实用程序来获取与ndctl所示类似的硬件级数据。清单17-2显示了DIMMID 0x0001的运行状况信息(ndctl术语中的nmem1等效项)。
17.2.1 ACPI规定的健康函数(_NCH, _NBS)
ACPI规范包括两种与供应商无关的方法,用于操作系统和管理软件,以调用它们来确定持久性内存设备的运行状况。
启动时操作系统可以调用Get NVDIMM Current Health Information(_NCH),以获取持久内存设备的当前运行状况并采取适当的操作。_NCH报告的值可能在运行时发生更改,应监视更改。_NCH包含健康信息,显示是否:
- 持久内存需要维护;
- 持久内存设备性能降低;
- 操作系统会假设在随后的电源事件中发生写持久性丢失;
- 操作系统会假设所有数据在随后的电源事件中都会丢失。
Get NVDIMM Boot Status(_NBS)允许操作系统使用与供应商无关的方法发现在运行时不会更改的持久内存运行状况。_NBS报告的最重要的属性是数据丢失计数(DLC)。应用程序和操作系统预计将使用数据丢失计数来帮助识别发生持久内存脏关机的罕见情况。有关如何正确使用此属性的详细信息,请参阅本章后面的“不安全/脏关机”章节。
17.2.2 供应商专有健康函数(_DSMs)
许多供应商可能希望在_NBS和_NCH中添加更多的健康属性。供应商可以自由设计自己的ACPI持久性内存设备专有方法(_DSM),供操作系统和特权应用程序调用。尽管供应商实现持久性内存运行状况发现的方式不同,但可能存在一些通用的运行状况属性来确定持久性内存设备是否需要服务。这些运行状况属性可以包括诸如持久性内存的总体运行状况摘要、当前持久性内存温度、持久性媒体错误计数和设备总生存期利用率等信息。许多操作系统(如Linux)都支持通过ndctl等工具检索和报告供应商独有的运行状况统计信息。Intel持久内存DSM接口文档位于https://docs.pmem.io/的“Related Specification”章节。
17.2.3 ACPI NFIT健康事件通知
由于潜在的服务质量损失,操作系统和特权应用程序可能不希望主动轮询持久内存设备以检索设备运行状况。因此,ACPI规范定义了一个被动通知方法,允许持久性存储器设备在设备运行状况发生重大变化时进行通知。持久性内存设备供应商和平台BIOS供应商决定哪些设备的运行状况更改足以触发NVDIMM固件接口表(NFIT)运行状况事件通知。在收到NFIT运行状况事件时,操作系统的通知将调用连接到持久性内存设备的_NCH或_DSM,并根据返回的数据采取适当的行动。
17.3 不安全/脏关机
持久性内存上的不安全或脏关机意味着持久性内存设备断电序列或平台断电序列可能无法将所有正在运行的数据从系统的持久性域写入持久性介质。(第2章描述持久性域)脏关机是一个非常罕见的事件,但它们可能由于各种原因发生,如物理硬件问题、功率峰值、热事件等。
持久性内存设备不知道是否有应用程序数据由于不完整的断电顺序而丢失。它只能检测是否发生了一系列可能丢失数据的事件。在最佳情况下,当脏关机发生时,可能没有任何应用程序正在写入数据。
这里描述的RAS机制要求平台BIOS和持久内存供应商维护一个持久滚动计数器,该计数器在检测到脏关机时递增。ACPI规范引用了数据丢失计数(DLC)等机制,该机制可以作为Get NVDIMM Boot Status(_NBS)持久内存设备方法的一部分信息而返回。
这里描述的RAS机制要求平台BIOS和持久内存供应商维护一个持久滚动计数器,该计数器在检测到脏关机时递增。ACPI规范引用了数据丢失计数(DLC)等机制,该机制可以作为Get NVDIMM Boot Status(_NBS)持久内存设备方法的一部分返回。
参考清单17-1中ndctl的输出,健康信息中报告了“shutdown_count”。类似地,清单17-2中来自ipmctl的输出将“LatchedDirtyShutdownCount”报告为脏关机计数器。对于这两个输出,值为1表示未检测到问题。
17.3.1 数据丢失计数(DLC)的应用
应用程序可能希望使用_NBS提供的DLC计数器来检测在将数据从系统的持久性域保存到持久性介质时是否可能发生数据丢失。如果可以检测到这种丢失,则应用程序可以使用自己特定的功能执行数据恢复或回滚。
应用的职责和可能的实施建议概述如下:
- 应用程序首先创建其初始元数据并将其存储在持久内存文件中:
- 应用程序通过操作系统专有的方式检索构成应用程序元数据所在逻辑卷的物理持久内存的DLC;
- 应用程序将当前逻辑数据丢失计数(LDLC)计算作为构成应用程序元数据所在的逻辑卷所有物理持久性内存的DLC的总和;
- 应用程序将当前LDLC存储在其元数据文件中,并确保LDLC的更新已刷新到系统的持久性域。这是通过使用一个flush来完成的,该flush强制将数据一直写到持久内存powerfail-safe域。(第2章包含有关将数据flush到持久性域的更多信息。)
- 应用程序确定应用程序元数据所在的逻辑卷的GUID或UUID,将其存储在其元数据文件中,并确保将GUID/UUID更新到持久性域。应用程序稍后将使用它来标识元数据文件是否已移动到另一个逻辑卷,在新的逻辑卷上,当前的DLC将不再有效;
- 应用程序在其元数据文件中创建并设置“clean”标志,并确保将clean标志更新到持久性域。应用程序使用此选项来确定应用程序是否在脏关机期间主动将数据写入持久设备。
- 每次应用程序运行并从持久内存检索其元数据时:
- 应用程序使用应用程序元数据所在的逻辑卷的当前UUID检查保存在其元数据中的GUID/UUID。如果它们匹配,那么LDLC描述的是应用程序正在使用同一个逻辑卷。如果它们不匹配,则DLC用于其他逻辑卷,不再适用。应用程序决定如何处理这个问题;
- 应用程序计算当前LDLC作为应用程序元数据所在的所有物理持久性内存的DLC之和;
- 应用程序将当前计算的LDLC与从其元数据中检索的保存的LDLC进行比较。
- 如果当前LDLC与保存的LDLC不匹配,则表示检测到一个或多个脏关机和可能数据丢失。如果它们确实匹配,则应用程序不需要进一步操作;
- 应用程序检查元数据中保存的“clean”标志的状态;如果未设置clean标志,则此应用程序在关闭失败时正在写入;
- 如果未设置清除标志,请使用应用程序的特定功能执行软件数据恢复或回滚;
- 应用程序将新的当前LDLC存储在其元数据文件中,并确保已将计数的更新刷到系统的持久性域。如果先前设置了clean标志,则需要取消设置;
- 应用程序在其元数据文件中设置clean标志,并确保clean标志的更新已刷到持久性域。
- 每次应用程序写入文件时:
- 在应用程序写入数据之前,它会清除其元数据文件中的“clean”标志,并确保该标志已刷到持久性域;
- 应用程序将数据写入其持久内存空间 ;
- 应用程序完成数据写入后,它会在其元数据文件中设置“clean”标志,并确保该标志已刷到持久性域。
PMDK库使这些步骤大大简化,并考虑了交错集配置。
17.4 本章小结
本章描述了一些可用于持久性内存设备的RAS特性,以及与持久性内存应用程序相关的RAS特性。它应该让您更深入地了解了不可纠正的错误以及应用程序如何响应这些错误,操作系统如何检测运行状况更改以提高应用程序的可用性,以及应用程序如何能够最好地检测脏关机并使用数据丢失计数器。




