18 远程持久内存
本章提供用于通过网络访问位于远程服务器上的持久内存的编程概念的概览。TCP/IP或者RDMA网络硬件和运行在包含持久内存服务器上的软件相结合,提供了直接远程访问持久内存的方法。
通过高性能网络连接直接访问远程内存对于大多数持久内存云开发来说是一个关键场景。典型的,在高可用或者高冗余场景,到持久内存的本地写数据不用考虑可靠性直到它被复制到两个或者更多远程持久内存设备上。我们在后面的章节描述了这个推送模型设计。
使用现有TPC/IP网络基础设施来访问远程持久内存是没有问题的,但本章聚焦于RDMA的使用。DMA使得平台上的数据移动负载挪到了硬件DMA引擎,这使得在数据移动过程中,可以把CPU释放出来做其他重要的工作。RDMA提供了相同的概念,使得在远程服务器间移动数据时,不需要CPU被牵涉进来。
本章内容和PMDK librpmem远程持久内存库,讨论时假设使用了RDMA,但讨论的这些概念也适用于其他网络连接技术和协议。
图Figure 18-1 概述了一个简单远程持久内存配置,该配置带有一个源系统,复制数据写到另一个远程目标系统的持久内存中。这展示了在源和目标上的持久内存使用。,它可用于读取源上DRAM的数据并写到远程目标系统上的持久内存上,或者从源持久内存中读取数据写到远程目标的DRAM中。

18.1 RDMA网络协议
RDMA网络协议在云和企业数据中心普遍使用,包括:
- InfiniBand是一种I/O体系结构和高性能规范,用于在高速、低延迟和高可扩展cpu、处理器和存储之间进行数据传输;
- RoCE (RDMA over Converged Ethernet) 是一个网络协议,在以太网上走RDMA;
- iWARP (Internet Wide Area RDMA Protocol) 是一种网络协议,在互联网协议上实现高效数据传输RDMA。
上面协议均支持使用RDMA从持久内存高性能移动数据。
RDMA协议由RDMA Wire Protocol Standards来规定,通过IBTA(InfiniBand Trade Association)和IEFT (Internet Engineering Task Force)规范来驱动。IBTA (https://www.infinibandta.org/)管理InfiniBand 和RoCE协议,IEFT (https://www.ietf.org/)管理iWARP。
低延迟RDMA网络协议允许NIC(network interface controller网络接口控制器)控制源节点缓存和目标节点缓冲之数据的移动,而不需要节点上CPU牵涉进来。事实上,RDMA读和RDMA写操作经常被认为是单边操作,因为移动数据所有需要的信息由源提供,目标节点上CPU不会被打扰甚至不知道有数据传输。
执行远程数据传输,来自目标节点缓冲的信息在远程操作开始前必须被传输到源。这需要配置本地源的RDMA资源和缓冲buffer。类似的,远程目标节点RDMA资源需要CPU资源被初始化并且报告给源。然而,一旦为RDMA传输设置了资源,并且应用程序使用CPU启动RDMA请求,那么NIC代表RDMA感知应用执行实际数据传输。
RDMA感知应用程序负责:
- 询问每个发起程序和目标系统上的每个NIC以确定支持的特性;
- 为RDMA点到点连接的每一端选择NIC ;
- 创建与选定NIC的连接,描述为RDMA保护域;
- 为每个NIC上的传入和传出消息分配队列,并将这些硬件资源分配给保护域
- 为RDMA分配DRAM或持久内存缓冲区,向NIC注册这些缓冲区,并将这些缓冲区分配给保护域。
多数支持RDMA的应用程序和库都使用三个基本的RDMA命令:
RDMA Write: 一种单边操作,只有发起者提供传输所需的所有信息。该传输是把数据写到远程目标节点。写入请求包含所有源和接收器缓冲区信息。远程目标系统通常不会被中断(不会接收到中断),因此完全不知道通过NIC发生的写操作。当发起方的NIC向目标发送写操作时,它将生成一个“软件写入完成中断”。软件写入完成中断意味着写入消息已发送到目标NIC,而不是写入完成。可选地,RDMA Writes可以使用一个立即选项,该选项将中断目标节点CPU,并允许在那里运行的软件立即收到“写入完成”的通知。
RDMA Read:一种单边操作,只有发起方提供传输所需的所有信息。此传输用于从远程目标节点读取数据。读取请求包含所有源缓冲区和目标接收器缓冲区信息,远程目标系统通常不会被中断(不会接收到中断),因此完全不知道通过NIC发生的读取操作。发起程序软件读取完成中断是一种确认,该读取已通过发起程序的NIC、网络、目标系统的NIC、目标内部硬件网格和内存控制器,一直遍历到DRAM或持久内存以检索数据。然后它一路返回到注册了“完成”通知的发起程序软件。
RDMA Send(和Receive):双面RDMA Send意味着发起方和目标方都必须提供完成传输所需的信息。这是因为当目标NIC接收到”RDMASend”时,目标NIC将被中断,并且在NIC在接收“RDMA Send”传输操作之前,需要设置硬件接收队列并用完成项进行预填充。来自发起应用程序的数据捆绑在一个小的、有限大小的缓冲区中,并发送到目标NIC。目标CPU将被中断以处理发送操作及其包含的任何数据。如果需要通知发起者接收到RDMA Send,或要将消息处理回给发起者,则在发起者设置了自己的接收队列并将完成项排队之后,必须以相反的方向发送另一个RDMA发送操作。RDMA Send命令的使用和有效负载的内容与应用的特定实现细节相关。RDMA Send通常用于记录和更新发起程序和目标之间的读写活动,因为目标应用程序没有发生数据移动的其他上下文。例如,由于没有很好的方法知道目标上的写入何时完成,所以通常使用RDMA Send来通知目标节点正在发生的事情。对于少量数据,RDMA发送非常有效,但它始终需要目标端交互才能完成。带有即时数据操作的RDMA写操作还将允许目标节点在写操作完成时被中断,作为一种不同的记账机制。
18.2 初始远程持久内存架构目标
第一个远程持久内存实现的目标是基于对与易失性内存一起使用的当前RDMA硬件和软件堆栈的变化最小(或者理想情况下,没有更改)。从网络硬件、中间件和软件体系结构的角度来看,写入远程易失性存储器与写入远程持久性存储器是相同的。知道一个特定的内存映射文件是由持久性内存和易失性内存支持的,这完全是应用程序维护的责任。网络堆栈中的较低层都不知道写入到持久内存区域或易失性内存。知道要为给定的目标连接使用哪个写持久化方法,并使这些远程写持久化的责任属于应用程序。
18.3 保证远程持久化
在本章之前,本书的大部分内容都集中在本地机器上持久内存的使用和编程上。现在您已经意识到使用持久性内存、持久性域的一些挑战,并且需要理解和使用刷新机制来确保数据是持久的。这些相同的编程概念和挑战适用于远程持久性内存,并附加了使其在现有网络协议和网络延迟内工作的限制。
SNIA-NVM编程模型(在第3章中描述)要求应用程序刷新已写入持久性内存的数据,以确保写入的数据进入持久性域。同样的要求也适用于远程持久内存的写入。RDMA写入或发送操作将数据从发起方节点移动到目标节点上的持久性内存后,需要将该写入或发送数据刷新到远程系统上的持久性域。或者,远程写入或发送数据需要绕过远程节点上的CPU缓存,以避免刷新。
不同的特定于供应商的平台特性给RDMA和远程持久内存增加了额外的挑战。Intel平台通常使用一种称为分配写入或直接数据IO(DDIO)的功能,允许将传入的写入直接放入CPU的三级缓存。任何想要读取数据的应用程序都可以立即看到数据。但是,启用了分配写操作意味着RDMA对持久性内存的写操作现在必须刷新到目标节点上的持久性域。
在Intel平台上,可以通过启用非分配写I/O流来禁用分配写操作,该流强制写数据绕过缓存并直接放入持久内存,由RDMA写接收器缓冲区的位置控制。这将减慢应用程序的速度,这些应用程序将立即接触新写入的数据,因为它们会招致将数据拉入CPU缓存的惩罚。但是,这简化了对持久内存的远程写入,因为可以避免在远程目标节点上刷新缓存。在Intel平台上使用非分配写入模式的另一个复杂问题是,必须为此写入模式启用整个PCI根复合体。这意味着,对于连接在PCI根复合体下游的任何设备,通过该PCI根复合体的任何入站写操作都将有写数据绕过CPU缓存,这可能会导致额外的性能延迟作为副作用。
Intel指定了两种将远程持久性内存写入持久性域的方法:
- 一种通用的远程复制方法,它不依赖于Intel的非分配写模式,并假定部分或全部远程写数据最终会出现在目标系统的CPU缓存中;
- 一种高性能设备远程复制方法,使用Intel平台特定的非分配写入模式,可能更适合于完全控制硬件配置以控制连接到哪个PCI根复合体的设备产品。
18.3.1 通用远程复制方法
通用远程复制方法(GPRRM)也称为通用服务器持久性方法(GPSPM),它依赖于发起者RDMA应用程序来维护用以前的RDMA写入请求写入的远程目标系统上的虚拟地址列表。当向持久内存发出所有远程写入时,应用程序将从发起方NIC向目标NIC发出RDMA发送请求。RDMA Send请求包含当目标节点上运行的应用程序软件中断系统以处理发送请求时,目标系统将使用的虚拟起始地址和长度的列表。应用程序遍历区域列表,使用优化的刷新机器指令(CLWB、CLFLUSHOPT等)将请求区域中的每个缓存线刷新到持久内存。完成后,需要一个SFENCE机器指令来限制以前的写入,并在处理其他写入之前强制它们完成。然后,目标系统上的应用程序回发RDMA发送请求,以中断已完成刷新操作的发起者软件。这是应用程序的一个指示,表明以前的写入已被持久化。图18-2概述了通用远程复制方法的操作顺序。
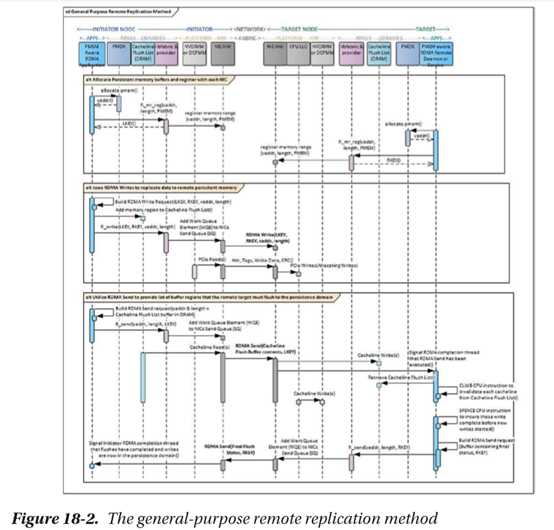
18.3.2 通用远程复制方法如何使数据持久化?
在RDMA写入或任何数量的写入被发送之后,写入数据将要么在L3 CPU缓存中(由于默认分配写入),要么在持久内存中(假设它不完全适合L3),其中可能有一些写入数据仍挂起在NIC内部缓冲区中。根据定义,RDMA发送请求将强制将先前的写入从NIC推送到目标L3 CPU缓存,并中断目标CPU。此时,以前发出的所有RDMA写入持久内存的操作现在都在L3或持久内存中。RDMA Send请求包含发起程序请求目标系统刷新到其持久性域的缓存线列表。目标系统发出优化的刷新指令,将列表中的每个缓存线刷新到持久性域。然后是一个SFENCE,以确保在处理新写操作之前完成这些写操作。此时,RDMA发送列表中先前刷新的写入现在是持久的。
18.3.3 通用远程复制方法的性能影响
通用远程复制方法要求发起者程序软件的RDMA遵循一个RDMA Send的RDMA Write写入数量。在目标NIC完成刷新请求的区域后,从目标发送的RDMA将返回到发起程序,以确认发起程序应用程序可以将这些写入视为永久性的。此附加的发送/接收/发送/接收消息对延迟和吞吐量有影响,从而使写入保持不变,并且延迟比设备远程复制方法高50%。额外的消息传递会影响在这些NIC上运行的所有RDMA连接的总体带宽和可伸缩性。
另外,如果需要持久化的RDMA写操作的大小很小,那么连接的效率就会急剧下降,因为额外的消息传递开销成为整个延迟的重要组成部分。此外,目标节点的CPU和缓存也将用于该操作。相同的数据基本上传输两次:一次从网卡(通过PCIe)传输到CPU L3高速缓存,然后从CPU L3高速缓存传输到内存控制器(iMC)。
18.3.4 设备远程复制方法
Intel平台上持久内存的用户可以使用非分配写流,方法是在特定的PCI根复合体上启用该功能,其中来自NIC的传入写将进入CPU的内部结构并输出到持久内存。使用非分配的写流,传入的RDMA写操作将绕过CPU缓存并直接进入持久性域。这意味着写入不需要由目标系统CPU刷新到持久性域。I/O管道仍需要刷新到持久性域。这可以通过向与RDMA写操作相同的RDMA连接上的任何内存地址发出一个小的RDMA读操作来更有效地实现;内存地址不需要是已写的或持久的。RDMA规范清楚地指出,RDMA读取将强制先前的RDMA写入首先完成。此排序规则也适用于目标NIC所连接的PCIe互连。PCIe读取将执行管道刷新并强制先前的PCIe写入首先完成。图18-3概述了前面描述的基本设备远程复制方法,通常称为设备持久性方法。

18.3.5 设备远程复制方法如何使数据持久化?
在目标系统上绕过CPU缓存,以便将入站RDMA Write写入到持久性内存,再加上RDMA和PCIe协议的排序语义,这就产生了使数据持久化的有效机制。由于对持久内存的RDMA Read读取将首先强制先前对持久内存和持久域的写入,因此在这些写入完成后返回的RDMA Read读取完成是发起程序应用程序确认这些写入现在是持久的。
第2章深入定义了持久性域,包括平台如何确保在断电的情况下所有写操作都从持久性域到达媒体。
18.3.6 设备远程复制方法的性能影响
使用RDMA Read的单次额外往返比通用服务器持久性方法大约低50%的延迟,该方法需要两个往返消息,然后才能将写入声明为持久。与第一种方法一样,随着要持久化的写操作的大小变小,RDMA读取往返开销成为整个延迟的重要组成部分。
18.4 通用软件体系结构
用于远程持久内存的软件堆栈通常使用第3章中讨论的相同内存映射文件。持久内存作为内存映射文件提供给RDMA应用程序。应用程序在连接的两端向本地NIC注册持久内存,生成的注册表项与发起程序共享,以便在RDMA读写请求中使用。这与传统的volatile DRAM与RDMA一起使用所需的过程完全相同。
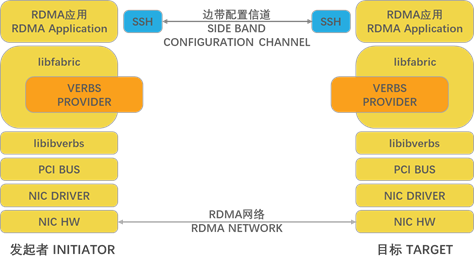
内核和应用程序级软件组件的分层通常用于允许应用程序同时使用持久内存和RDMA连接。IBTA定义了verbs接口,这些接口通常由NIC的内核驱动程序和中间件软件应用程序库实现。附加的库可以在verb层之上分层,以便通过实现库的通用API和NIC特定的提供程序提供通用RDMA服务。
在Linux上,Open Fabric Alliance(OFA)libibverbs库提供了ring-3接口,用于为支持IB、RoCE和iWARP RDMA网络协议的NIC配置和使用RDMA连接。OFA libfabric ring-3应用程序库可以在libibverbs之上分层,以提供可与典型RDMA NIC一起使用的通用高级公共API。这个公共API需要一个提供者插件来实现特定网络协议的公共API。OFA网站包含许多示例应用程序和性能测试,可以在Linux上与各种RDMAcapable NIC一起使用。这些示例提供了PMDK librpmem库的主干。
Windows通过ring-3 SMB Direct应用程序库实现远程装载的NTFS卷,该应用程序库提供了许多存储协议,包括通过RDMA的块存储。
图18-4提供了Linux上典型RDMA应用程序的基本高级体系结构,使用了所有公开可用的库和接口。注意,通常需要单独的边带连接来设置RDMA连接本身。
18.5 librpmem架构和在复制中的应用
PMDK在librpmem库中实现了通用远程复制方法和设备远程复制方法。从PMDK v1.7开始,librpmem库实现对远程系统上持久内存的本地写操作的同步和异步复制。librpmem是一个低级库,与libpmem类似,它允许其他库使用其复制功能。
libpmemobj使用同步写入模型,这意味着本地发起程序写入和所有远程复制的写入必须在本地写入完成并返回到应用程序之前完成。libpmemobj库还实现了一个简单的主动-被动复制体系结构,其中所有持久内存事务都是通过主动发起方节点驱动的,而远程目标则是被动备用的,复制写数据。虽然被动目标系统复制了最新的写入数据,但实现不会尝试使用远程系统进行故障转移、故障恢复或负载平衡。以下各节描述此实现的重大性能缺陷。
libpmemobj使用配置文件中提供的本地内存池配置信息来描述远程网络连接的内存映射文件。安装在每个远程目标系统上的远程rpmemd程序将启动,并使用安全加密的套接字连接连接到发起程序上的librpmem库。通过此连接,librpmem将代表libpmemobj建立与每个目标系统的RDMA点对点连接,确定目标支持的持久化方法(通用或设备方法),分配远程内存映射的持久化内存文件,在远程NIC上注册持久化内存,并检索注册内存的结果内存键。
一旦建立到所有目标的所有RDMA连接,所有必需的队列都被实例化,并且内存缓冲区都已分配和注册,libpmemobj库就可以开始将所有应用程序写入数据远程复制到其本地内存映射文件。当应用程序在libpmemobj中调用pmemobj_persist()时,库将在librpmem中生成相应的rpmem_persist()调用,然后调用libfabric fi_write()来执行RDMA写入。然后,librpmem通过调用libfabric fi_Read()或fi_Send()来启动RDMA Read或Send persistence方法(取决于对当前启用的目标节点的当前配置的理解)。设备远程复制方法使用RDMA Read,通用远程复制方法使用RDMA Send。
图18-5概述了前面描述的高级组件和接口,并由使用librpmem和libpmemobj的发起程序和远程目标系统使用。
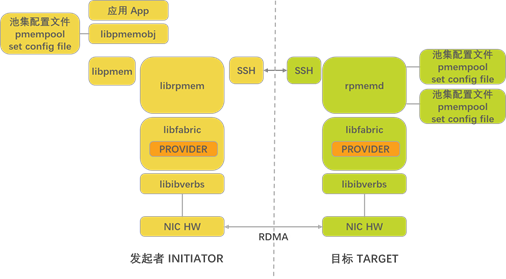
以下介绍了主要组件(如图18-5所示),以帮助您了解PMDK的远程复制功能所使用的高级体系结构:
librpmem–PMDK Remote RDMA Access Library:发起方节点的容器,用于所有与使用RDMA进行远程复制相关的发起方PMDK功能。
rpmemd – PMDK Remote RDMA Configuration Daemon:目标节点的容器,用于所有与使用RDMA进行远程复制相关的目标PMDK功能。它将阻止对已配置为远程使用的pmempool集的任何本地访问,并执行通用远程复制方法所需的远程目标中断处理程序。
Initiator and Target SSH: librpmem和rpmemd库都使用这个组件来建立一个简单的套接字连接,关闭先前打开的套接字连接,并来回发送通信数据包。
Libfabric: OFA定义的高级ring-3应用程序API,用于以与结构和供应商无关的方式设置和使用结构连接。此高级接口支持RoCE、InfiniBand和iWARP,以及使用libfabric特定传输提供程序的Intel Omni-Path体系结构产品和其他网络协议。
Libibverbs: OFA定义的基于RDMA结构的高级接口。这个高级接口支持RoCE、InfiniBand和iWARP,通常用于大多数Linux发行版。
Target Node Platform Configuration File: 由IT管理员或用户生成的简单文本文件,用于描述远程目标节点的平台功能。此文件描述影响可使用的持久性方法的特定功能,即启用ADR的平台、由NIC启用的非分配写流和平台类型。它还指定rpmemd将侦听的默认套接字连接端口。
Initiator Node PMDK pmempool Set Configuration File: 现有的持久性内存池集配置文件由系统或应用程序管理员生成,该文件描述将被视为本地平台上的持久性内存池的本地文件集。它还描述了本地复制的本地文件和远程复制的远程目标主机名。
Target Node PMDK pmempool Set Configuration File: 现有的持久性内存池集配置文件由系统或应用程序管理员生成,该文件描述将被视为本地平台上的持久性内存池的本地文件集。在目标节点上,此集是发起方节点将数据复制到的文件集合。
Initiator and Target Node Operating System syslog: librpmem和rpmemd用于为调试和非调试信息输出有用数据的每个节点上的标准Linux系统日志。由于来自rpmemd的信息在发起程序系统上很少可见,当rpmemd使用“-d”(调试)运行时选项启动时,大量信息将输出到目标系统syslog。即使没有启用调试,rpmemd也会输出套接字事件,如open、close、create、lost connection和类似的RDMA事件。
18.5.1 使用池集配置远程复制
您可能已经熟悉使用池集(在第7章中介绍)libpmemobj来初始化远程复制,这需要两个这样的池集文件。启用libpmemobj的应用程序在发起端使用的文件,必须描述本地内存池并指向目标节点上的池集配置文件;而目标节点上的池集文件,必须描述目标系统共享的内存池。
清单18-1显示了一个池集文件,该文件将允许复制本地写入到“remotepool.set “在远程主机上。
Listing 18-1. poolwithremotereplica.set – An example of replicating local data to a remote host
PMEMPOOLSET 256G /mnt/pmem0/pool1
REPLICA user@example.com remotepool.set清单18-2显示了一个池集文件,它描述了为远程访问共享的内存映射文件。在许多方面,远程池集文件与常规池集文件相同,但它必须满足额外的要求:
- 存在于rpmemd配置文件中指定的池集目录中;
- 应通过其名称进行唯一标识,启用rpmem的应用程序必须使用该名称复制到指定的内存池;
- 不能定义任何额外的本地或远程副本。
Listing 18-2. remotereplica.set – An example of how to describe the memory pool on the remote host
PMEMPOOLSET 256G /mnt/pmem1/pool218.5.2 性能考虑
一旦通过远程网络连接访问持久内存,与写入远程SSD或传统块存储设备相比,可以实现显著更低的延迟。这是因为RDMA硬件将远程写入数据直接写入最终的持久性内存位置,而远程复制到固态硬盘需要RDMA写入远程服务器上的DRAM,然后执行第二个本地DMA操作,将远程写入数据从易失性DRAM移动到SSD或其他传统块存储设备上的最终存储位置。
将数据复制到远程持久内存的性能挑战是,虽然512KiB或更大的块大小可以获得良好的性能,但随着要复制的写操作的大小越来越小,网络开销将成为总延迟的较大部分,性能可能会受到影响。
如果持久内存用作SSD替换,则典型的本机块存储大小为4K,避免了小传输带来的一些低效。如果持久内存取代了传统的SSD,并且数据被远程写入SSD,那么持久内存的延迟改进可以是10倍或更多。
librpmem中实现的同步复制模型意味着,本地持久性内存中的小数据结构和指针更新会导致小的、非常低效的RDMA写入,随后是小的RDMA读取或发送,以使少量的写入数据持久化。与只向本地持久内存写入相比,这会导致性能显著下降。它使得复制性能非常依赖于本地持久内存写入序列,而本地持久内存写入序列在很大程度上依赖于应用程序工作负载。一般来说,平均请求大小越大,给定工作负载所需的rpmem_persist()调用数越少,将提高确保数据持久化所需的总体延迟。
可以使用单个RDMA Read或Send跟踪多个RDMA Writes写操作,以使前面的所有写操作持久化。这减少了RDMA写操作的大小对建议的解决方案的总体性能的影响。但使用这种缓解措施时,请记住,在RDMA Read completion返回或收到RDMA Send并得到确认之前,不能保证任何RDMA写入都是持久的。允许这种方法的实现是在rpmem_flush()和rpmem_drain()API调用对中实现的,其中rpmem_flush()执行RDMA写入并立即返回,rpmem_drain()发布RDMA读取并等待其完成(在发布时,它不是在Write/send模型中实现的)。
有很多性能方面的考虑,包括所使用的高级网络模型。传统的同类最佳网络体系结构通常依赖于发起者和目标之间的拉动模型。在拉取模型中,发起程序从目标请求资源,但目标服务器只有在拥有资源和连接带宽时才通过RDMA Read拉取数据。此以服务器为中心的视图允许目标节点处理数百或数千个连接,因为它完全控制所有连接的所有资源,并在选择时启动网络事务。由于持久内存的速度和低延迟,可以在发起方和目标方预先分配和注册了内存资源的情况下使用推送模型,直接由RDMA写入数据,而无需等待服务器端的资源协调。微软的SNIA DevCon RDMA演示更详细地描述了推/拉模型:(https://www.snia.org/sites/default/files/SDC/2018/presentations/PM/Talpey_Tom_Remote_Persistent_Memory.pdf)。
18.5.3 远程复制错误处理
失去套接字连接或失去RDMA连接,librpmem复制将失败。从rpmem_persist()、rpmem_flush()和rpmem_drain()返回的任何错误状态通常被视为不可恢复的故障来处理。librpmem API的libpmemobj用户应将此视为失去套接字或RDMA连接的情况,并应等待所有剩余的librpmem API调用完成,调用rpmem_close()关闭连接并清理堆栈,然后强制应用程序退出。当应用程序重新启动时,文件将在两端重新打开,libpmemobj将只检查文件元数据。建议在使用pmempool sync(1)命令同步本地和远程内存池之前不要继续操作。
18.5.4 向复制世界问好
libpmemobj远程复制的漂亮之处在于它不需要对现有的libpmemobj应用程序进行任何更改。如果您使用任何libpmemobj应用程序,并为其提供使用远程副本的池集文件配置,它将简单地开始复制,无需编码。
为了演示如何复制持久内存,我们仔细看一个Hello World程序,它直接使用librpmem库演示复制过程。清单18-3显示了C程序的一部分,它将“Hello world”消息写入远程内存。如果它发现英文信息已经存在,它会将其翻译成西班牙语并将其写回远程内存。我们在清单中给出了关键程序部分。
Listing 18-3. The main routine of the Hello World program with replication
37 #include <assert.h>
38 #include <errno.h>
39 #include <unistd.h>
40 #include <stdio.h>
41 #include <stdlib.h>
42 #include <string.h>
43
44 #include <librpmem.h>
45
46 /*
47 * English and Spanish translation of the message
48 */
49 enum lang_t {en, es};
50 static const char *hello_str[] = {
51 [en] = "Hello world!",
52 [es] = "¡Hola Mundo!"
53 };
54
55 /*
56 * structure to store the current message
57 */
58 #define STR_SIZE 100
59 struct hello_t {
60 enum lang_t lang;
61 char str[STR_SIZE];
62 };
63
64 /*
65 * write_hello_str -- write a message to the local memory
66 */
67 static inline void
68 write_hello_str(struct hello_t *hello, enum lang_t lang)
69 {
70 hello->lang = lang;
71 strncpy(hello->str, hello_str[hello->lang], STR_SIZE);
72 }
…
…
104 int
105 main(int argc, char *argv[])
106 {
107 /* for this example, assume 32MiB pool */
108 size_t pool_size = 32 * 1024 * 1024;
109 void *pool = NULL;
110 int created;
111
112 /* allocate a page size aligned local memory pool */
113 long pagesize = sysconf(_SC_PAGESIZE);
114 assert(pagesize >= 0);
115 int ret = posix_memalign(&pool, pagesize, pool_size);
116 assert(ret == 0 && pool != NULL);
117
118 /* skip to the beginning of the message */
119 size_t hello_off = 4096; /* rpmem header size */
120 struct hello_t *hello = (struct hello_t *)(pool + hello_off);
121
122 RPMEMpool *rpp = remote_open("target", "pool.set", pool, pool_size,
123 &created);
124 if (created) {
125 /* reset local memory pool */
126 memset(pool, 0, pool_size);
127 write_hello_str(hello, en);
128 } else {
129 /* read message from the remote pool */
130 ret = rpmem_read(rpp, hello, hello_off, sizeof(*hello), 0);
131 assert(ret == 0);
132
133 /* translate the message */
134 const int lang_num = (sizeof(hello_str) / sizeof(hello_ str[0]));
135 enum lang_t lang = (enum lang_t)((hello->lang + 1) % lang_num);
136 write_hello_str(hello, lang);
137 }
138
139 /* write message to the remote pool */
140 ret = rpmem_persist(rpp, hello_off, sizeof(*hello), 0, 0);
141 printf("%s\n", hello->str);
142 assert(ret == 0);
143
144 /* close the remote pool */
145 ret = rpmem_close(rpp);
146 assert(ret == 0);
147
148 /* release local memory pool */
149 free(pool);
150 return 0;
151 }- 第68行: 用于将消息写入本地内存的简单帮助程序;
- 第115行: 分配足够大的内存块,该内存块与页面大小对齐。所需的块大小是硬编码的,而如果要使此内存块可用于RDMA传输,则需要对齐;
- 第122行: remote_open() 例程创建或打开远程内存池;
- 第126-127行: 本地内存池在此初始化。它只在创建远程内存池时执行一次,因此不包含任何消息;
- 第130行: 远程内存池中的消息将被读取到本地内存中;
- 第134-136行: 如果正确读取了来自远程内存池的消息,则会在本地翻译该消息;
- 第140行: 新初始化或转换的消息将写入远程内存池;
- 第145行: 关闭远程内存池;
- 第149行: 释放远程内存池。
整个过程中最后缺少的部分是如何设置远程复制。这一切都是在清单18-4所示的remote_open() 例程中完成的。
Listing 18-4. A remote_open routine from the Hello World program with replication
74 /*
75 * remote_open -- setup the librpmem replication
76 */
77 static inline RPMEMpool*
78 remote_open(const char *target, const char *poolset, void *pool,
79 size_t pool_size, int *created)
80 {
81 /* fill pool_attributes */
82 struct rpmem_pool_attr pool_attr;
83 memset(&pool_attr, 0, sizeof(pool_attr));
84 strncpy(pool_attr.signature, "HELLO", RPMEM_POOL_HDR_SIG_LEN);
85
86 /* create a remote pool */
87 unsigned nlanes = 1;
88 RPMEMpool *rpp = rpmem_create(target, poolset, pool, pool_ size, &nlanes,
89 &pool_attr);
90 if (rpp) {
91 *created = 1;
92 return rpp;
93 }
94
95 /* create failed so open a remote pool */
96 assert(errno == EEXIST);
97 rpp = rpmem_open(target, poolset, pool, pool_size, &nlanes, &pool_attr);
98 assert(rpp != NULL);
99 *created = 0;
100
101 return rpp;
102 }- 第88行: 可以创建或打开远程内存池。当它第一次使用时,必须创建它,以便以后可以打开它。我们首先尝试在这里创建它;
- 第97行: 在这里,我们试图打开远程内存池。我们假设它存在是因为在创建尝试期间接收到错误代码(EEXIST)。
18.5.5 执行示例
Hello World应用程序执行后输出如清单18-5所示。
Listing 18-5. An output from the Hello World application for librpmem
[user@initiator]$ ./hello
Hello world!
[user@initiator]$ ./hello
¡Hola Mundo!清单18-6显示了目标持久内存池的内容,我们在其中会看到“Hola Mundo”字符串。
Listing 18-6. The ¡Hola Mundo! snooped on the replication target
[user@target]$ hexdump –s 4096 –C /mnt/pmem1/pool2
00001000 01 00 00 00 c2 a1 48 6f 6c 61 20 4d 75 6e 64 6f |......Hola Mundo| 00001010 21 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |!...............|
00001020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 00002000 18.6 本章小结
必须知道,通用远程复制方法和设备远程复制方法都不是理想的方法,因为需要特定于供应商的平台特性才能使用非分配写入,这增加了影响整个PCI根复合体性能的复杂性。相反,使用分配写操作刷新远程写操作需要目标系统的令人不快的中断来拦截RDMA发送请求并刷新发送缓冲区中包含的区域列表。在云环境中唤醒远程节点非常令人不快,因为有来自许多不同连接的成百上千个入站RDMA请求;如果可能,请避免这样做。
现在有云服务提供商使用这两种方法,并获得了惊人的性能结果。如果将持久内存用作远程访问的SSD的替代品,则可以大大减少延迟。
作为远程持久性支持的第一次迭代,我们关注应用程序/库的更改,以实现这些高级持久性方法,而不需要更改硬件、固件、驱动程序或协议。在出版之时,IBTA和IETF为持久性存储器的一个新的wire协议扩展起草的草案已经接近完成。这将为RDMA到持久内存提供本机硬件支持,并允许硬件实体将每个I/O路由到其目标内存设备,而无需更改分配写入模式,也不会对连接到同一根端口的辅助设备的性能产生不利影响。有关RDMA新扩展(特别是远程持久性扩展)的更多详细信息,请参阅附录E。
RDMA协议扩展只是进一步开发远程持久内存的一步。已经确定了其他几个改进领域,并已对远程持久性内存用户社区发布,包括远程操作的原子性、高级错误处理(包括RAS)、远程持久性内存的动态配置和自定义设置,以及远程/目标复制端实际0%的CPU利用率。
正如这本书所展示的,解锁持久内存的真正潜力可能需要对现有软件和应用程序架构采取新的方法。希望本章能让您对这个复杂的主题、使用远程持久内存的挑战以及在释放真正的性能潜力时要考虑的软件体系结构的许多方面有一个概览。




