19 高级主题
本章涵盖了我们在本书前面简要描述过的几个主题,前面章节怕分散大家注意力并没有进一步讨论。本章会对这些主题进行深入讨论,以供参考。
19.1 非一致内存访问NUMA
NUMA是一种用于多处理的计算机内存设计,其中内存访问时间取决于相对于处理器的内存位置。NUMA用于对称多处理(SMP)系统。SMP系统是一个“紧密耦合、共享一切”的系统,在这个系统中,在单一操作系统下工作的多个处理器可以通过公共总线或“互连”路径访问彼此的内存。使用NUMA,处理器访问自己的本地内存比非本地内存更快(另一个处理器的本地内存或处理器之间共享的内存)。NUMA的好处仅限于特定的工作负载,特别是在数据通常与某些任务或用户紧密关联的服务器上。
当CPU可以访问其本地内存时,CPU内存访问总是最快的。通常,CPU插槽和最近的内存库定义一个NUMA节点。当一个CPU需要访问另一个NUMA节点的内存时,它不能直接访问它,而是需要通过拥有该内存的CPU来访问它。图19-1显示了一个双插槽系统,DRAM和持久内存均表示为“内存”。
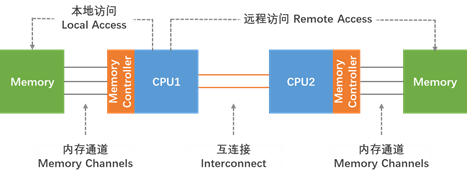
在NUMA系统中,处理器和内存库之间的距离越大,处理器访问该内存库的速度就越慢。因此,对于性能敏感的应用程序,应进行配置,以便它们从最近的内存库分配内存。
性能敏感的应用程序也应该配置为在一组核心上执行,特别是在多线程应用程序的情况下。由于一级缓存通常很小,如果在一个内核上执行多个线程,则每个线程可能会逐出前一个线程访问的缓存数据。当操作系统尝试在这些线程之间执行多任务,并且这些线程继续逐出彼此的缓存数据时,它们的执行时间的很大一部分用于缓存线替换。此问题称为缓存抖动。因此,我们建议您将多线程应用程序绑定到NUMA节点,而不是单个核心,因为这允许线程在多个级别(第一级、第二级和最后一级缓存)上共享缓存线,并最大限度地减少了对缓存填充操作的需要。但是,如果所有线程都在访问相同的缓存数据,则可以将应用程序绑定到单个核心。numactl允许您将应用程序绑定到特定的核心或NUMA节点,并将与核心或核心集相关联的内存分配给该应用程序。
19.1.1 NUMACTL Linux 实用工具
在Linux上,我们可以使用numactl实用程序来显示NUMA硬件配置,并控制哪些核心和线程应用程序进程可以运行。numactl包中包含的libnuma库为内核支持的NUMA策略提供了一个简单的编程接口。它可以提供比numactl实用程序更细粒度的优化控制。更多信息见numa(7)手册页。
numactl –hardware命令显示系统中可用NUMA节点的清单。输出只显示易失性存储器,而不是持久性存储器。在下一节中,我们将展示如何使用ndctl命令来显示持久内存的NUMA局部性。NUMA节点的数量并不总是等于套接字的数量。例如,AMD Threadripper 1950X有1个套接字和2个NUMA节点。numactl的以下输出是从一个双插槽Intel Xeon Platinum 8260L处理器服务器收集的,每个插槽总共385GiB DDR4,每槽196GiB。
# numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
node 0 size: 192129 MB
node 0 free: 187094 MB
node 1 cpus: 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
node 1 size: 192013 MB
node 1 free: 191478 MB
node distances:
node 0 1
0: 10 21
1: 21 10节点距离是相对距离,而不是以纳秒或毫秒为单位的实际基于时间的延迟。 numactl允许您将应用程序绑定到特定的核心或NUMA节点,并将与核心或核心集相关联的内存分配给该应用程序。表19-1描述了numactl提供的一些有用选项。

19.1.2 NDCTL Linux实用程序
ndctl实用程序用于为操作系统创建称为命名空间的持久内存容量,以及枚举、启用和禁用dimm、区域和命名空间。使用–v(verbose)选项可以显示NUMA节点(NUMA_节点)持久内存dimm(-D)、区域(-R)和命名空间(-N)属于哪个。清单19-1显示了双套接字系统的区域和名称空间。我们可以将numa_节点与numactl命令显示的相应numa节点关联起来。
Listing 19-1. Region and namespaces for a two-socket system
# ndctl list -Rv
{ "regions":[
{
"dev":"region1",
"size":1623497637888,
"available_size":0,
"max_available_extent":0,
"type":"pmem",
"numa_node":1,
"iset_id":-2506113243053544244,
"persistence_domain":"memory_controller",
"namespaces":[
{
"dev":"namespace1.0",
"mode":"fsdax",
"map":"dev",
"size":1598128390144,
"uuid":"b3e203a0-2b3f-4e27-9837-a88803f71860",
"raw_uuid":"bd8abb69-dd9b-44b7-959f-79e8cf964941",
"sector_size":512,
"align":2097152,
"blockdev":"pmem1",
"numa_node":1
}
]
},
{
"dev":"region0",
"size":1623497637888,
"available_size":0,
"max_available_extent":0,
"type":"pmem",
"numa_node":0,
"iset_id":3259620181632232652,
"persistence_domain":"memory_controller",
"namespaces":[
{
"dev":"namespace0.0",
"mode":"fsdax",
"map":"dev",
"size":1598128390144,
"uuid":"06b8536d-4713-487d-891d-795956d94cc9",
"raw_uuid":"39f4abba-5ca7-445b-ad99-fd777f7923c1",
"sector_size":512,
"align":2097152,
"blockdev":"pmem0",
"numa_node":0
}
]
}
]
}19.1.3 MLC Intel内存延迟检查器
要获取Intel系统上NUMA节点之间的绝对延迟数,可以使用“Intel内存延迟检查器”(Intel MLC),该检查器可从https://software.intel.com/en-us/articles/intel-memory-latency-checker获得。【现已转到https://software.intel.com/en-us/articles/intelr-memory-latency-checker,已下载mlc_v3.8.tgz】
Intel MLC提供了使用命令行参数指定的几种模式:
- –latency_matrix 打印本地和跨socket内存延迟的矩阵;
- –bandwidth_matrix 打印本地和跨插槽内存带宽的矩阵;
- –peak_injection_bandwidth打印各种读写比率下平台的峰值内存带宽;
- –idle_latency 打印平台的空闲内存延迟;
- –loaded_latency 打印平台的加载内存延迟;
- –c2c_latency 打印平台的缓存到缓存数据传输延迟。
在没有参数的情况下执行mlc或mlc_avx512,使用每个测试的默认参数和值依次运行所有模式,并将结果写入终端。下面的示例显示在双插槽Intel系统上的运行延迟矩阵。
# ./mlc_avx512 --latency_matrix -e -r
Intel(R) Memory Latency Checker - v3.6
Command line parameters: --latency_matrix -e -r
Using buffer size of 2000.000MiB
Measuring idle latencies (in ns)...
Numa node
Numa node 0 1
0 84.2 141.4
1 141.5 82.4- –latency_matrix 打印本地和跨socket内存延迟的矩阵;
- -e 意味着硬件预取器状态不会被修改;
- -r 是延迟线程的随机访问读取。
MLC可用于测试DAX或FSDAX模式下的持久内存延迟和带宽。常用的参数包括:
- -L 请求使用大页面(2MB)(假设已启用);
- -h 请求用于DAX文件映射的大页面(1GB);
- -J 指定将在其中创建mmap文件的目录(默认情况下不创建文件)。此选项与–j互斥;
- -P CLFLUSH 用于将存储逐出到持久内存。
例子: 顺序读延迟:
# mlc_avx512 --idle_latency –J/mnt/pmemfs
Random read latency:
# mlc_avx512 --idle_latency -l256 –J/mnt/pmemfs19.1.4 NUMASTAT实用工具
Linux上的numastat实用程序显示处理器和操作系统的每个NUMA节点内存统计信息。在没有命令选项或参数的情况下,它显示来自内核内存分配器的NUMA命中和未命中系统统计信息。默认的numastat统计信息以内存页为单位显示每个节点的数量,例如:
$ sudo numastat
node0 node1
numa_hit 8718076 7881244
numa_miss 0 0
numa_foreign 0 0
interleave_hit 40135 40160
local_node 8642532 2806430
other_node 75544 5074814- numa_hit 是否按预期在此节点上成功分配内存;
- numa_miss 是在该节点上分配的内存,尽管进程首选某些不同的节点。每个numa_miss在另一个节点上都有一个numa_foreign;
- numa_foreign 是用于此节点的内存,但实际分配给另一个节点。每个numa_foreign在另一个节点上都有一个numa_miss;
- interleave_hit 在此节点上成功地按预期分配了交错内存;
- local_node 是在该节点上运行进程时在此节点上分配的内存;
- other_node 在另一个节点上运行进程时在此节点上分配的内存。
19.1.5 Intel VTune Profiler 平台分析器
在Intel系统上,您可以使用Intel VTune Profiler(以前称为VTune Amplifier)(在第15章中讨论)来显示CPU与内存统计信息,包括CPU缓存的命中率与未命中率以及对DDR与永久内存的数据访问。它还可以描述系统的配置,以显示哪些内存设备实际位于哪个CPU上。
19.1.6 IPMCTL 实用工具
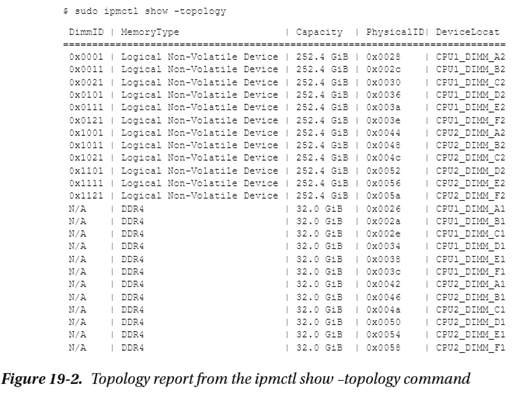
持久性内存供应商和服务器特定的实用程序也可以用于显示DDR和持久性内存设备拓扑,以帮助确定哪些设备与哪些CPU插槽关联。例如,如果数据可用,ipmctl show -topology命令将显示DDR和永久内存(非易失性)设备及其物理内存插槽位置(见图19-2)。
19.1.7 BIOS调整选项
BIOS包含许多调整选项,可以更改CPU、内存、持久内存和NUMA的行为。位置和名称可能因服务器平台类型、服务器供应商、持久内存供应商或BIOS版本而异。但是,大多数适用的可调选项通常可以在“Memory Configuration”和“Processor Configuration”下的“Advanced”菜单中找到。有关每个可用选项的说明,请参阅系统BIOS用户手册。您可能需要使用应用程序测试几个BIOS选项,以了解哪些选项最有价值。
19.1.8 自动NUMA平衡
当需要许多CPU和大量内存时,会遇到硬件的物理限制。重要的限制是CPU和内存之间的通信带宽有限。NUMA架构解决了这个问题。当一个应用程序的进程的线程访问同一个NUMA节点上的内存时,它通常表现得最好。自动NUMA平衡将任务(可以是线程或进程)移到它们正在访问的内存附近。它还将应用程序数据移到更靠近引用它的任务的内存中。当自动NUMA平衡处于活动状态时,内核会自动执行此操作。大多数操作系统都实现了这个特性。本节讨论Linux上的特性;请参阅Linux发行版文档以了解具体选项,因为它们可能有所不同。
默认情况下,在大多数Linux发行版中都会启用自动NUMA平衡,当操作系统检测到它在具有NUMA属性的硬件上运行时,它将在启动时自动激活。要确定功能是否已启用,请使用以下命令:
$ sudo cat /proc/sys/kernel/numa_balancing值1(true)表示该功能已启用,而值0(零/false)表示该功能已禁用。
自动NUMA平衡使用多个算法和数据结构,这些算法和数据结构仅在系统上启用自动NUMA平衡时才处于活动状态并进行分配,使用以下几个简单步骤:
- 任务扫描器定期扫描地址空间并标记内存,以便在下次访问数据时强制出现页面错误;
- 下一次访问数据将导致NUMA提示错误。基于此故障,数据可以迁移到与访问内存的线程或进程相关联的内存节点;
- 为了保持一个线程或进程正在使用的CPU和正在访问的内存在一起,调度器按共享的数据将任务分组。
使用numactl对应用程序进行手动NUMA调整将覆盖任何系统范围内的自动NUMA平衡设置。自动NUMA平衡简化了NUMA机器上高性能的工作负载调整。在可能的情况下,我们建议静态地调整工作负载,分区到每个节点。某些对延迟敏感的应用程序(如数据库)通常在手动配置时工作得最好。然而,在大多数其他用例中,自动NUMA平衡应该有助于提高性能。
19.2 使用具有持久内存的卷管理器
我们可以提供持久内存作为块设备,在其上可以创建文件系统。应用程序可以使用标准的文件API访问持久内存,或者从文件系统中映射一个文件,并通过load/ store操作直接访问持久内存。第2章和第3章描述了可访问性选项。
卷管理器的主要优点是提高了抽象性、灵活性和控制能力。逻辑卷可以起有意义的名称,如“数据库”或“web”。随着空间需求的变化,卷可以动态调整大小,并在运行系统的卷组内的物理设备之间迁移。
在NUMA系统上,CPU和DRR以及直接连接到它的持久内存之间存在一个局部性因素。通过互连访问不同CPU上的内存会导致较小的延迟损失。延迟敏感的应用程序(如数据库)理解这一点,并协调其线程在其访问的内存所在的同一个套接字上运行。
与SSD或NVMe相比,持久内存相对较小。如果您的应用程序需要一个单独的文件系统,该文件系统消耗系统上的所有持久内存,而不是每个NUMA节点使用一个文件系统,则可以使用软件卷管理器使用系统的所有容量创建联结或条带(RAID0)。例如,如果在双插槽系统上每个CPU插槽有1.5TiB的持久内存,则可以构建联结或条带(RAID0)来创建3TiB文件系统。如果本地系统冗余比大型文件系统更重要,则可以跨NUMA节点镜像(RAID1)持久内存。一般来说,在物理服务器之间复制数据以实现冗余效果更好。第18章详细讨论了远程持久内存,包括使用远程直接内存访问(RDMA)跨系统传输和复制数据。
卷管理器产品太多,无法在本书中为所有产品提供手把手的教程。在Linux上,可以使用设备映射器(dmsetup)、多设备驱动程序(mdadm)和Linux卷管理器(LVM)创建使用多个NUMA节点的容量的卷。因为大多数现代Linux发行版默认使用LVM作为引导磁盘,所以我们假设您有一些使用LVM的经验。Linux文档和Web上有大量的信息和教程。
图19-3显示了两个区域,在这两个区域上,我们可以创建一个fsdax或扇区类型的名称空间,用于创建相应的/dev/pmem0和/dev/pmem1设备。使用/dev/pmem[01],我们可以创建一个LVM物理卷,然后将其组合起来创建一个卷组。在卷组中,我们可以根据需要自由地创建尽可能多的请求大小的逻辑卷。每个逻辑卷可以支持一个或多个文件系统。

例如,如果要为每个区域创建多个名称空间或使用fdisk或parted对/dev/pmem*设备进行分区,我们还可以创建许多可能的配置。这样做可以提供更大的灵活性和结果逻辑卷的隔离。但是,如果物理NVDIMM出现故障,则影响会更大,因为它会根据配置影响部分或全部文件系统。
创建复杂的RAID卷组可以保护数据,但代价是不能有效地使用所有的数据持久内存容量。此外,复杂的RAID卷组不支持某些应用程序可能需要的DAX功能。
19.3 mmap() MAP_SYNC 标志
在Linux内核v4.15中引入了MAP_SYNC标志,它确保在允许进程修改直接映射的数据之前完成任何所需的文件系统元数据写入。MAP_SYNC标志被添加到mmap() 系统调用中以请求同步行为;特别是,此标志提供的保证是:
当块可写地映射到该映射的页表中时,也可以保证在崩溃后在该文件的偏移处可见。
这意味着文件系统不会静默地重新定位块,它将确保文件的元数据处于一致状态,以便出现问题的块在崩溃后出现。这是通过确保在允许进程写入受该元数据影响的页之前完成任何所需的元数据写入来完成的。
当使用MAP_SYNC映射持久内存区域时,内存管理代码将检查受影响文件是否存在挂起的元数据写入。然而,它实际上不会flush那些写出来的内容。相反,页面被映射为只读,并带有一个特殊的标志,当进程第一次尝试对其中一个页面执行写操作时,会强制出现页面错误。然后,错误处理程序将同步刷新任何脏的元数据,设置允许写入的页面权限,然后返回。此时,进程可以安全地写入页面,因为所有必要的元数据更改都已将其写入持久存储。
其结果是一个相对简单的机制,其性能将远远优于当前可用的替代方法,即在每次写入持久内存之前手动调用fsync()。Fsync()中的额外IO可能会导致进程暂停,并阻塞本应是简单内存写入的内容,产生意外延迟。
Linux程序员手册中的mmap(2)手册页描述了映射同步标志,如下所示:
MAP_SYNC (since Linux 4.15)。此标志仅对MAP_SHARED_VALIDATE映射类型可用;MAP_SHARED类型的映射将自动忽略此标志。只有支持DAX(持久内存直接映射)的文件才支持此标志。对于其他文件,使用此标志创建映射将导致EOPNOTSUPP错误。
具有此标志的共享文件映射提供了这样的保证:虽然某些内存可写地映射到进程的地址空间中,但即使在系统崩溃或重新启动后,它仍将在同一文件中的同一偏移处可见。结合使用适当的CPU指令,这为此类映射的用户提供了一种更有效的方法,使数据修改持久化。
19.4 本章小结
在本章中,我们介绍了一些有关持久性内存的更高级主题,包括大型内存系统上的页面大小注意事项、NUMA感知及其如何影响应用程序性能、如何使用卷管理器创建跨多个NUMA节点的DAX文件系统以及mmap() 的映射同步标志。本书有意省略了其他主题,如BIOS优化,因为它是特定于供应商和产品的。持久内存产品的性能和基准测试留给外部资源,因为在本书中有太多的工具(vdbench、sysbench、fio等),每个工具都有太多的选项。




