
性能之重
极致性能是某些产品生存在这个世界的根本。
追求极致性能也因此成为编程高手存活的意义所在。

持久内存编程指南—乱译连载 (16.PMDK内部:重要算法和数据结构)
本章描述了libpmemobj的体系结构和内部工作原理。我们还讨论了在libpmemobj的设计和实现过程中所做选择的原因。有了这些知识,您可以准确地推理使用此库编写的代码的语义和性能特征。

持久内存编程指南—乱译连载 (15.性能分析与性能)
持久内存系统的分析和性能优化技术与无持久内存系统的那些技术类似。本章概述了理解性能的一些重要概念。也提供了指导用于刻画已存在无持久内存应用的特征和理解是否适用于持久内存。最后,提出了运行在持久内存平台上应用性能分析和调优的重要度量指标,包含一些例子,如何使用VTune Profiler来收集数据。
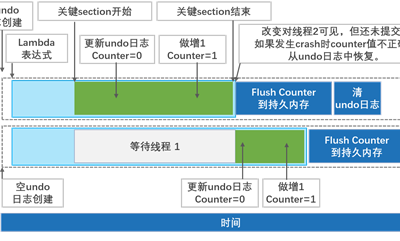
持久内存编程指南—乱译连载 (14.并发性和持久内存)
尽管为持久性内存构建应用程序是一项具有挑战性的任务,但是当需要为持久性内存创建多线程应用程序时,这项任务会更加困难。当多个线程可以更新持久内存中的相同数据时,您需要在多线程环境中处理数据一致性。

持久内存编程指南—乱译连载 (13.真实应用启用持久内存)
本章介绍了如何使用PMDK中的libpmemobj为流行的开源MariaDB数据库创建持久内存感知存储引擎。在应用程序中使用持久性内存可以在意外系统关闭时提供连续性,并通过将数据存储在靠近CPU的位置(可以以内存总线的速度访问)来提高性能。虽然数据库引擎通常使用内存缓存来提高性能(这需要时间来预热),但持久内存在应用程序启动时提供了立即预热的缓存。
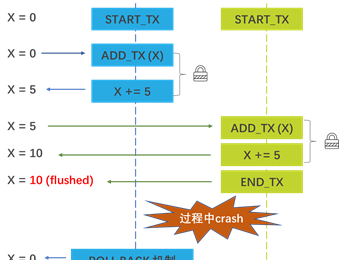
持久内存编程指南—乱译连载 (12.调试持久内存应用程序)
本章介绍了每种工具并描述了如何使用它们。在开发周期的早期发现问题可以节省以后无数小时调试复杂代码的时间。本章介绍了三种有价值的工具:Persistence Inspector、pmemcheck和pmreorder,持久性内存程序员希望将它们集成到开发和测试周期中以检测问题。我们演示了这些工具在检测许多不同类型的常见编程错误方面的用处。

持久内存编程指南—乱译连载 (11.为持久内存设计数据结构)
本章介绍如何设计持久内存的数据结构,并考虑其特性和功能。我们了讨论碎片化以及为什么在持久性内存的情况下会出现问题。我们还提出了几种保证数据一致性的不同方法;使用事务是最简单、最不易出错的方法。其他方法,如写时拷贝或版本控制,可以执行得更好,但它们很难正确实现。

持久内存编程指南—乱译连载 (10.持久内存的易失性使用)
本章展示了持久性内存的大容量是如何用来保存易失性应用程序数据的。应用程序可以选择从DRAM或持久内存或两者中分配和访问数据。memkind是一个非常灵活和易于使用的库,其语义类似于开发人员经常使用的libc的 malloc/free API。libvmemcache是一个可嵌入的轻量级内存缓存解决方案,它允许应用程序以可伸缩的方式有效地使用持久内存的大容量。libvmemcache是GitHub上的一个开源项目,位于https://github.com/pmem/vmemcache。
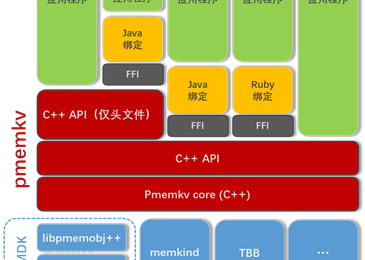
持久内存编程指南—乱译连载 (9.pmemkv: 持久内存KV库)
在本章中,我们已经展示了一个熟悉的KV数据库对于更广泛的云软件开发人员受众来说是如何使用持久内存并直接访问数据的简单方法。模块化设计、灵活的引擎API以及与许多最流行的云编程语言的集成使得pmemkv成为云本地软件开发人员的直观选择。作为一个开源的轻量级库,它可以很容易地集成到现有的应用程序中,以便立即开始利用持久内存。
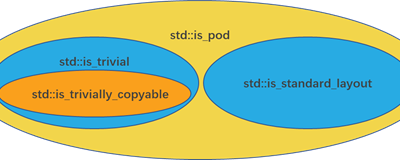
持久内存编程指南—乱译连载 (8. libpmemobj-cpp 版本)
本章介绍libpmemobj-cpp库。它使得创建应用程序不易出错,并且与标准C++ API相似,使得修改现有的易失性程序更容易使用持久内存。我们还列出了这个库的局限性以及在开发过程中必须考虑的问题。

持久内存编程指南—乱译连载 (7. libpmemobj: 本地事务对象存储)
本章描述了libpmemobj库,设计用于简化持久内存编程。通过提供那些支持原子操作、事务和预订/发布特性的API,使得创建保证数据完整性的应用,更不易于出错。
